데이터 분석 및 전처리시 자주 사용되진 않지만 필수적으로 알아두어야 할 방법들입니다.
- explode, Reverse explode, melt, cut, qcut
여기선 다루지 않지만 행(row), 열(column)을 쉽게 조작하게 도와주는 stack(), unstack() 함수도 유용합니다.
explode
list로 이루어진 데이터(column)를 다수의 행으로 펼쳐주는 방법, explode() 를 사용하면 손쉽게 해결할 수 있습니다.
df = pd.DataFrame({
'SEG': ['A', 'B'],
'VALUE': [[17, 23, 54], [19, 28, 51]]
})
df.explode('VALUE')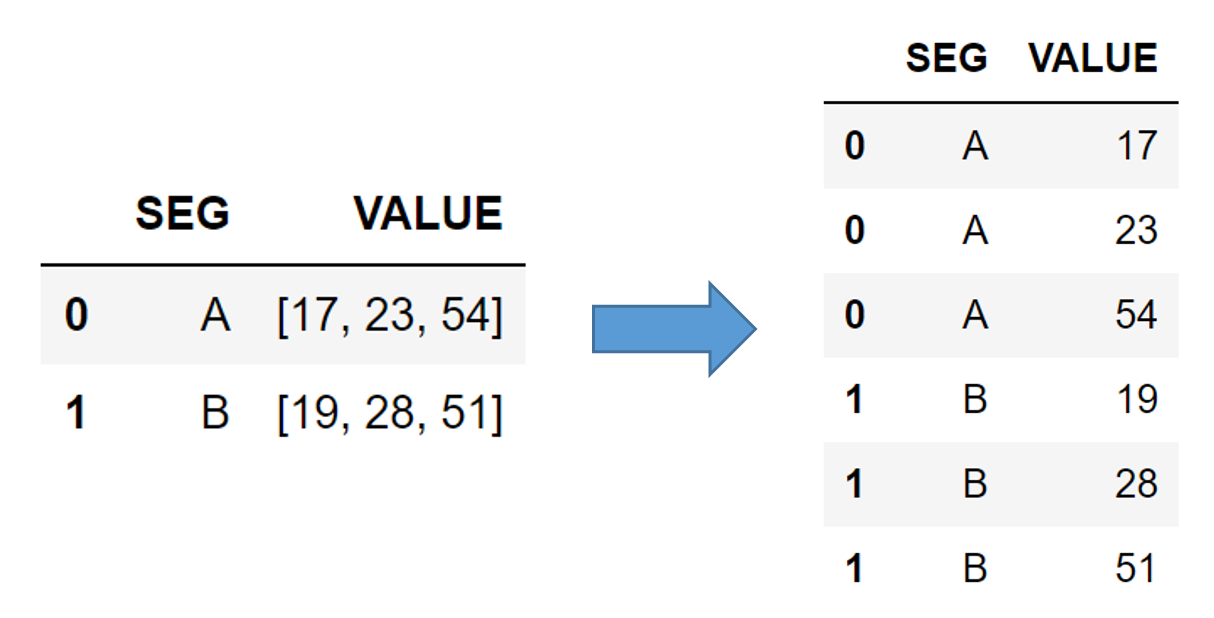
Reverse explode
위 방법의 반대입니다.
각 seg 별로 값을 list 형태로 합쳐줄 수 있습니다.
# as_index : index 해제
# agg : 각 SEG가 가지고 있는 VALUE를 tolist()함
ep_df.groupby('SEG', as_index = False).agg(lambda x: x.tolist())
melt
열을 행으로 펼쳐주고, 새로운 열을 생성합니다. 행과 열을 프로덕트(product)하여 column을 row value로 펼쳐줍니다. melt()를 활용합니다.
df = pd.DataFrame({
'SEG': ['A', 'B'],
'VALUE_1': [17, 23],
'VALUE_2': [19, 28],
})
df.melt(id_vars = ['SEG'], value_vars = ['VALUE_1', 'VALUE_2'],
var_name = 'VALUE_SEG', value_name = 'VALUES')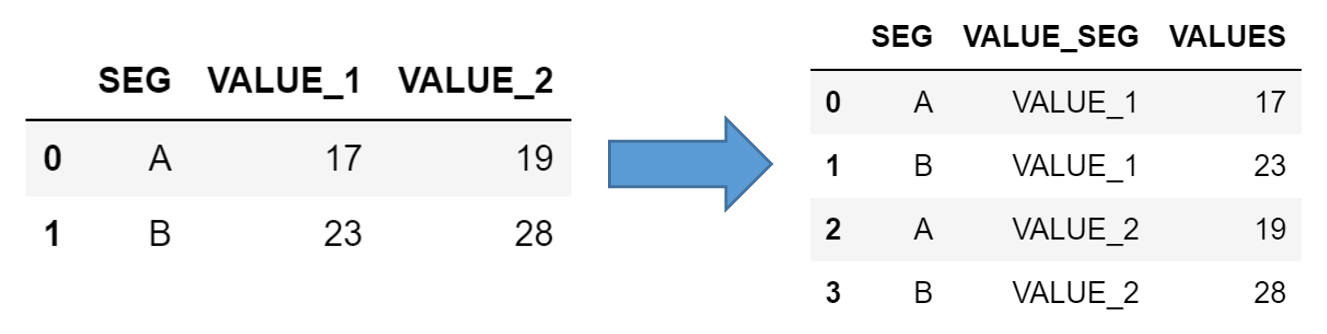
stack() 을 활용하면 동일한 결과를 얻을 수 있습니다.
df.set_index('SEG').stack().to_frame(name = 'VALUES').reset_index()
cut, quct을 활용한 category encoding
숫자 형태 데이터에 category encoding을 수행하고 싶을때,
qcut(), cut() 을 활용하면 원하는 전처리를 수행할 수 있습니다.
df = pd.DataFrame({
'AGES': [11, 16, 18,
21, 24, 29,
30, 35, 36,
40, 42, 43]
})
age_bins = [10, 20, 30, 40, 50]
df['AGE_SEG_cut'] = pd.cut(df['AGES'], age_bins)
df['AGE_SEG_qcut'] = pd.qcut(df['AGES'], q = 5)
'# 기타 공부한 것들 > 파이썬_etc.' 카테고리의 다른 글
| Useful Python Decorator 알아보기 (0) | 2021.07.31 |
|---|---|
| 파이썬 re 모듈을 활용한 정규표현식 간단 설명과 예제 (0) | 2021.06.01 |
| 파이썬(Python), 알아두면 유용한 방법들 (0) | 2021.06.01 |
| 파이썬 의존 패키지 복사하기 (0) | 2021.05.19 |
| pd.merge에서 join 예제 (0) | 2020.03.27 |