Abstract
Convolutional Neural Networks define an exceptionally powerful class of models, but are still limited by the lack of ability to be spatially invariant to the input data in a computationally and parameter efficient manner. In this work we introduce a new learnable module, the Spatial Transformer, which explicitly allows the spatial manipulation of data within the network. This differentiable module can be inserted into existing convolutional architectures, giving neural networks the ability to actively spatially transform feature maps, conditional on the feature map itself, without any extra training supervision or modification to the optimisation process. We show that the use of spatial transformers results in models which learn invariance to translation, scale, rotation and more generic warping, resulting in state-of-the-art performance on several benchmarks, and for a number of classes of transformations.
CNN은 여전히 강력하지만 spatillay invariant하기 때문에 제한적인 부분이 존재한다.
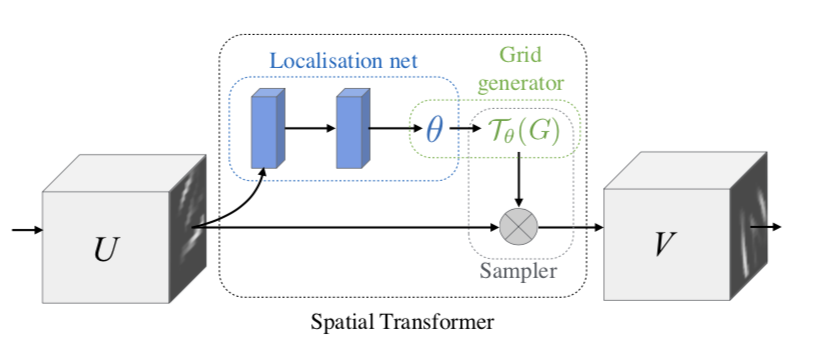
네트워크에서 공간적으로 데이터를 조작할 수 있는 Spatial Transformer를 소개한다.
이 모듈은 최적화 과정에서 여분의 학습 조정이 필요없이 조건 하에서 스스로 특징맵을 공간적으로 변환할 수 있다.
translation, scale, rotation, and more generic warping에 대한 invariance를 학습하며, SOTA를 확인하였다.
요약
- CNN의 한계 중 하나는 공간 상에서 크기가 변하거나 회전하거나 위치를 이동하였을 때 즉, 공간적인 변화가 있을 경우 물체를 잘 탐지하지 못하는 문제가 있다.
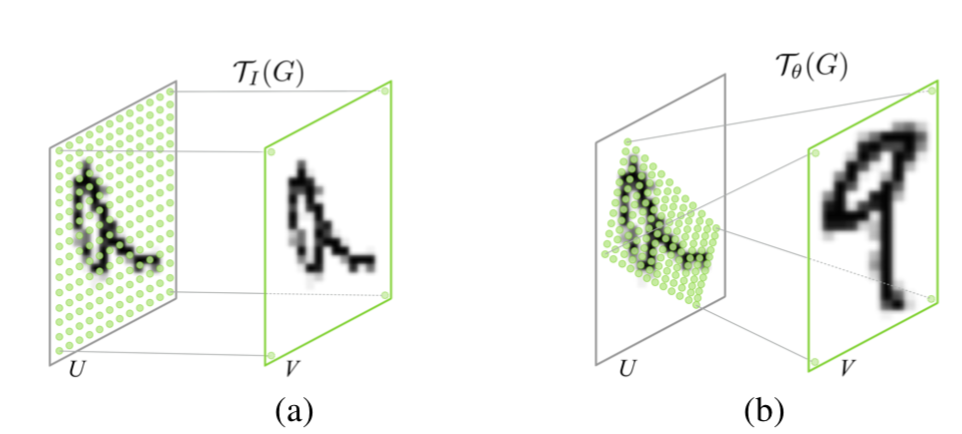
- spatial transform은 찌그러트리거나 회전시키는 등의 노이즈가 첨가된 이미지를 통해 적절히 추론하여 적절한 아웃풋을 도출해내는 모듈이다.
- Localisation net은 input을 통해 적절히 추론할 output을 만들어낼 transform matrix를 찾는다.
- Grid Generator은 transform matrix(localization set에서 찾아진)를 실질적으로 매핑하는 단계이다.
- Sampler는 Grid Generator가 만들어낸 값들을 하나하나 읽어오게 된다.
- Deformable CNN(2017)과 비교하여 보면 좋다. (이 논문은 2015 NIPS) - 가장 중요한 차이점은 Deformable은 기본 CNN연산에 offset을 추가하여 계산량이 증가하지 않지만, 이 논문은 Sampler에서 interpolation을 해주게 될때 연산량이 증가하게 된다는 점이다.
Reference
Jaderberg, M., Simonyan, K., & Zisserman, A. (2015). Spatial transformer networks. In Advances in neural information processing systems (pp. 2017-2025).
'# Paper Abstract Reading' 카테고리의 다른 글
| You Only Look Once: Unified, Real-Time Object Detection (0) | 2019.08.11 |
|---|---|
| Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (0) | 2019.07.16 |
| Bag of Tricks for Image Classification with Convolutional Neural Networks (0) | 2019.05.31 |
| Auto-Encoding Variational Bayes (0) | 2019.05.31 |
| Distilling the Knowledge in a Neural Network (0) | 2019.05.25 |