Abstract
We introduce YOLO9000, a state-of-the-art, real-time object detection system that can detect over 9000 object categories. First we propose various improvements to the YOLO detection method, both novel and drawn from prior work. The improved model, YOLOv2, is state-of-the-art on standard detection tasks like PASCAL VOC and COCO. Using a novel, multi-scale training method the same YOLOv2 model can run at varying sizes, offering an easy tradeoff between speed and accuracy. At 67 FPS, YOLOv2 gets 76.8 mAP on VOC 2007. At 40 FPS, YOLOv2 gets 78.6 mAP, outperforming state-of-the-art methods like Faster R-CNN with ResNet and SSD while still running significantly faster. Finally we propose a method to jointly train on object detection and classification. Using this method we train YOLO9000 simultaneously on the COCO detection dataset and the ImageNet classification dataset. Our joint training allows YOLO9000 to predict detections for object classes that don’t have labelled detection data. We validate our approach on the ImageNet detection task. YOLO9000 gets 19.7 mAP on the ImageNet detection validation set despite only having detection data for 44 of the 200 classes. On the 156 classes not in COCO, YOLO9000 gets 16.0 mAP. YOLO9000 predicts detections for more than 9000 different object categories, all in real-time.
9000개의 오브젝트를 탐지할 수 있는 실시간 객체 탐지기인 YOLO9000을 소개한다.
첫 번째로, YOLO보다 성능을 향상시켰다.
YOLOv2는 PASCAL VOC, COCO 데이터 셋에서 최고 성능을 달성했다.
multi-scale 방법을 사용하는 YOLOv2는 속도와 정확도 사이의 트레이드 오프관계를 쉽게 해결하면서 다양한 크기에서 실행될 수 있다.
VOC 2007에서 67 fps, 76.8 mAP를 달성했고, 빠른 속도를 보이는 SSD나 ResNet을 사용한 Faster R-CNN보다 높은 성능을 보여주었다.
마지막으로 우리는 객체 탐지와 분류를 동시에 학습할 수 있는 방법을 제안한다.
이 방법을 사용한 YOLO9000은 ImageNet 분류 데이터 셋과 COCO 데이터 셋을 동시에 학습한다.
이 학습 방법은 YOLO900이 라벨링 되지 않은 데이터에서 해당 객체의 클래스를 추론할 수 있게끔 한다.
우리는 ImageNet 탐지 작업에서 이 방법을 검증했다.
YOLO9000은 200개의 클래스 중에서 44개에 대한 탐지 데이터만 가지고 있음에도 불구하고 검증 셋에서 19.7 mAP를 달성했다.
COCO에 포함되지 않은 156개의 클래스에서, YOLO900은 16.0 mAP를 달성했다.
YOLO9000은 실시간으로 9000개의 다른 카테고리를 예측한다.
요약
- YOLO의 단점은 성능이 떨어지고, recall이 낮다.
- YOLO에서 사용하던 fc layer를 없애고 anchor box 방식을 채택하고 (448, 448; 이미지 크기)대신 (416, 416)을 사용함. 그 이유는 물체가 대부분 이미지의 중심에 존재하기 때문에 짝수 셀보다는 홀수 셀로하는게 좋다고 함. 짝수면 bbox가 4개의 셀을 걸치게 되고, 홀수인 경우는 1개의 셀에만 걸치기 때문에 좋다.
- (13, 13) feature map의 이전 (26, 26) feature map을 (13, 13, 2048)로 만들어서 (13, 13) feature map에 concat했다. 이로 인해 1% 의 향상을 얻었다.
- Detector가 다양한 이미지 크기에 대응하기 위해 다양한 이미지 크기를 사용하여 학습시켰다.(320 ~ 608 image resolution)
- ImageNet Classification에서 (224, 224)로 학습시킨 후, (448, 448)로 fine tuning하니 성능이 좀 높아졌다.
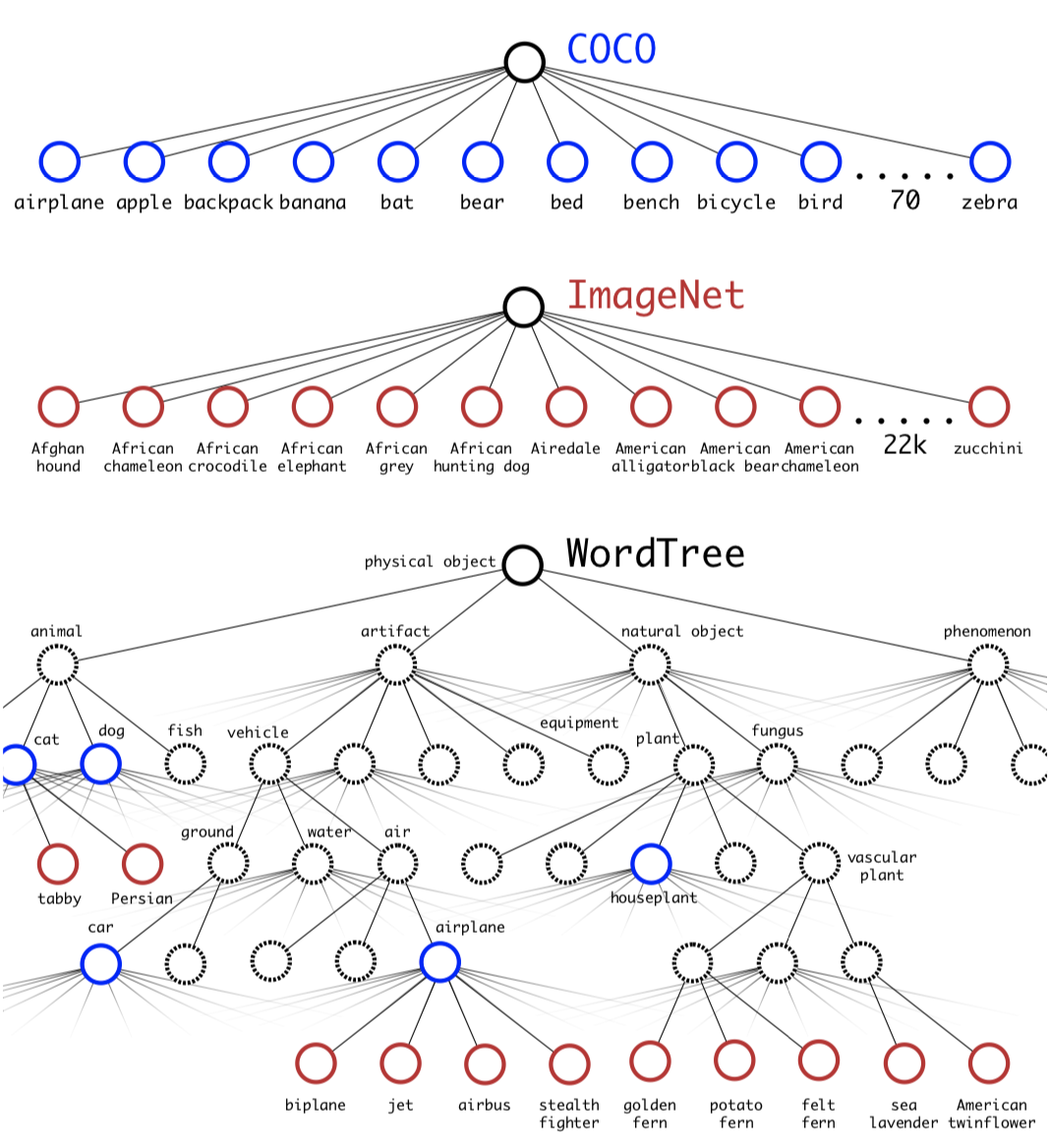
- WordTree를 구축하여서 총 1369개의 클래스를 구성하여 학습시켰지만, 큰 성능의 차이를 보여주진 못하였다.
- YOLOv2는 빠르고 정확하다. YOLO9000은 성능보다는 데이터셋의 구성에 더 초점을 두었다.

Reference
Redmon, J., & Farhadi, A. (2017). YOLO9000: better, faster, stronger. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7263-7271).