이글은 다음 문서를 참조합니다.
www.tensorflow.org/guide/keras/train_and_evaluate
(번역은 자력 + 파파고 + 구글 번역기를 사용하였으니, 부자연스럽더라도 양해바랍니다.)
Training & evaluation from tf.data Datasets
지금까지 loss, metrics, optimizers, validation_data, validation_split에 대해서 다루었습니다.
지금부터는 tf.data DataSet을 통해 데이터를 어떻게 다루는지 살펴보자.
tf.data API는 TensorFlow 2.0에서 빠르고 확장 가능한 방식으로 데이터를 로드하고 사전 처리하기 위한 유틸리티의 집합입니다.
DataSet을 통해 fit(), evaluate(), predict() 를 사용할 수 있습니다.
model = get_compiled_model()
# First, let's create a training Dataset instance.
# For the sake of our example, we'll use the same MNIST data as before.
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
# Shuffle and slice the dataset.
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
# Now we get a test dataset.
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_dataset = test_dataset.batch(64)
# Since the dataset already takes care of batching,
# we don't pass a `batch_size` argument.
model.fit(train_dataset, epochs=3)
# You can also evaluate or predict on a dataset.
print('\n# Evaluate')
model.evaluate(test_dataset)DataSet은 epoch가 끝날때마다 reset되므로 다음 epoch에서 재사용되어질 수 있습니다.
이러한 DataSet으로부터 구체적인 배치의 수만큼 학습시키길 원한다면, 다음 epoch으로 넘어가기전에 DataSet을 사용하여 얼만큼의 training steps를 거칠것인지를 다루는 steps_per_epoch 인자를 사용하세요.
이렇게 하면 각 epoch때마다 DataSet이 reset되지 않고, 대신 다음 배치만큼만 사용하게됩니다. 무한하지 않은 dataset은 결국 run-out-of-data가 될 것입니다.
model = get_compiled_model()
# Prepare the training dataset
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
# Only use the 100 batches per epoch (that's 64 * 100 samples)
model.fit(train_dataset, epochs=3, steps_per_epoch=100)
Using a validation dataset
DataSet 인스턴스로 validation_data를 사용할 수 있습니다.
model = get_compiled_model()
# Prepare the training dataset
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
# Prepare the validation dataset
val_dataset = tf.data.Dataset.from_tensor_slices((x_val, y_val))
val_dataset = val_dataset.batch(64)
model.fit(train_dataset, epochs=3, validation_data=val_dataset)각 epoch이 끝날때마다 모델은 validation loss, metrics를 계산하고, 반복할 것입니다.
validation_steps를 사용하면 steps_per_epoch과 같은 효과를 얻을 수 있습니다.
model = get_compiled_model()
# Prepare the training dataset
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
# Prepare the validation dataset
val_dataset = tf.data.Dataset.from_tensor_slices((x_val, y_val))
val_dataset = val_dataset.batch(64)
model.fit(train_dataset, epochs=3,
# Only run validation using the first 10 batches of the dataset
# using the `validation_steps` argument
validation_data=val_dataset, validation_steps=10)검증 데이터셋은 각 사용 후 재설정됩니다.(Epoch부터 Epoch까지 항상 동일한 표본에 대해 평가하게 됨).
DataSet에선 validation_split을 사용할 수 없습니다.
Other input formats supported
넘파이 배열과 DataSet외에도 Pandas dataframe, python generator를 사용해 keras를 학습시킬 수 있습니다.
일반적으로, 데이터가 작거나 메모리에 적당한 데이터라면 넘파이 배열이나 DataSets를 추천합니다.
Using sample weighting and class weighting
입력 데이터와 대상 데이터 외에도 fit() 사용 시 표본 가중치 또는 class 가중치를 모델에 전달할 수 있습니다.
- Numpy data일 경우 : sample_weight, class_weight
- DataSets일 경우 : (input_batch, target batch, sample_weight_batch)
"sample weights"는 총 손실을 계산할 때 각 샘플이 배치에서 얼마나 많은 가중을 받아야 하는지를 구체적으로 담은 배열입니다. 흔히 불균형 분류 문제에 사용되어집니다.(부족한 데이터를 가진 class에 더 높은 가중을 주는 경우). 사용된 가중치가 1과 0인 경우, 총 손실에 특정 샘플의 기여를 무시하는 손실 함수를 위한 mask로서 사용될 수 있습니다.
"class weights"는 클래스에 따라 샘플들이 가져야하는 가중에 대한 배열입니다. 예를 들어, 0이 1보다 2배 적다면 class_weight={0:1., 1:0.5}와 같이 사용할 수 있습니다.
다음은 클래스 가중치 또는 샘플 가중치를 사용하여 클래스 #5(MNIST 데이터 세트의 숫자 "5")의 올바른 분류에 더 중요성을 부여하는 Numpy 예입니다.
import numpy as np
class_weight = {0: 1., 1: 1., 2: 1., 3: 1., 4: 1.,
# Set weight "2" for class "5",
# making this class 2x more important
5: 2.,
6: 1., 7: 1., 8: 1., 9: 1.}
model.fit(x_train, y_train,
class_weight=class_weight,
batch_size=64,
epochs=4)
# Here's the same example using `sample_weight` instead:
sample_weight = np.ones(shape=(len(y_train),))
sample_weight[y_train == 5] = 2.
model = get_compiled_model()
model.fit(x_train, y_train,
sample_weight=sample_weight,
batch_size=64,
epochs=4)다음은 DataSet을 사용한 예입니다.
sample_weight = np.ones(shape=(len(y_train),))
sample_weight[y_train == 5] = 2.
# Create a Dataset that includes sample weights
# (3rd element in the return tuple).
train_dataset = tf.data.Dataset.from_tensor_slices(
(x_train, y_train, sample_weight))
# Shuffle and slice the dataset.
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
model = get_compiled_model()
model.fit(train_dataset, epochs=3)
Passing data to multi-input, multi-output models
앞의 예에서는 단일 입력(764,)와 단일 출력(10,)을 사용했습니다. 다중 입력/출력 일때는 어떻게 해야할까요?
(None - timesteps, 10 - features)로 이루어진 시계열 입력과 (32, 32, 3)으로 이루어진 이미지 입력을 생각해 봅시다. 모델은 점수와 5class로 구성된 확률분포를 output으로 가집니다.
from tensorflow import keras
from tensorflow.keras import layers
image_input = keras.Input(shape=(32, 32, 3), name='img_input')
timeseries_input = keras.Input(shape=(None, 10), name='ts_input')
x1 = layers.Conv2D(3, 3)(image_input)
x1 = layers.GlobalMaxPooling2D()(x1)
x2 = layers.Conv1D(3, 3)(timeseries_input)
x2 = layers.GlobalMaxPooling1D()(x2)
x = layers.concatenate([x1, x2])
score_output = layers.Dense(1, name='score_output')(x)
class_output = layers.Dense(5, activation='softmax', name='class_output')(x)
model = keras.Model(inputs=[image_input, timeseries_input],
outputs=[score_output, class_output])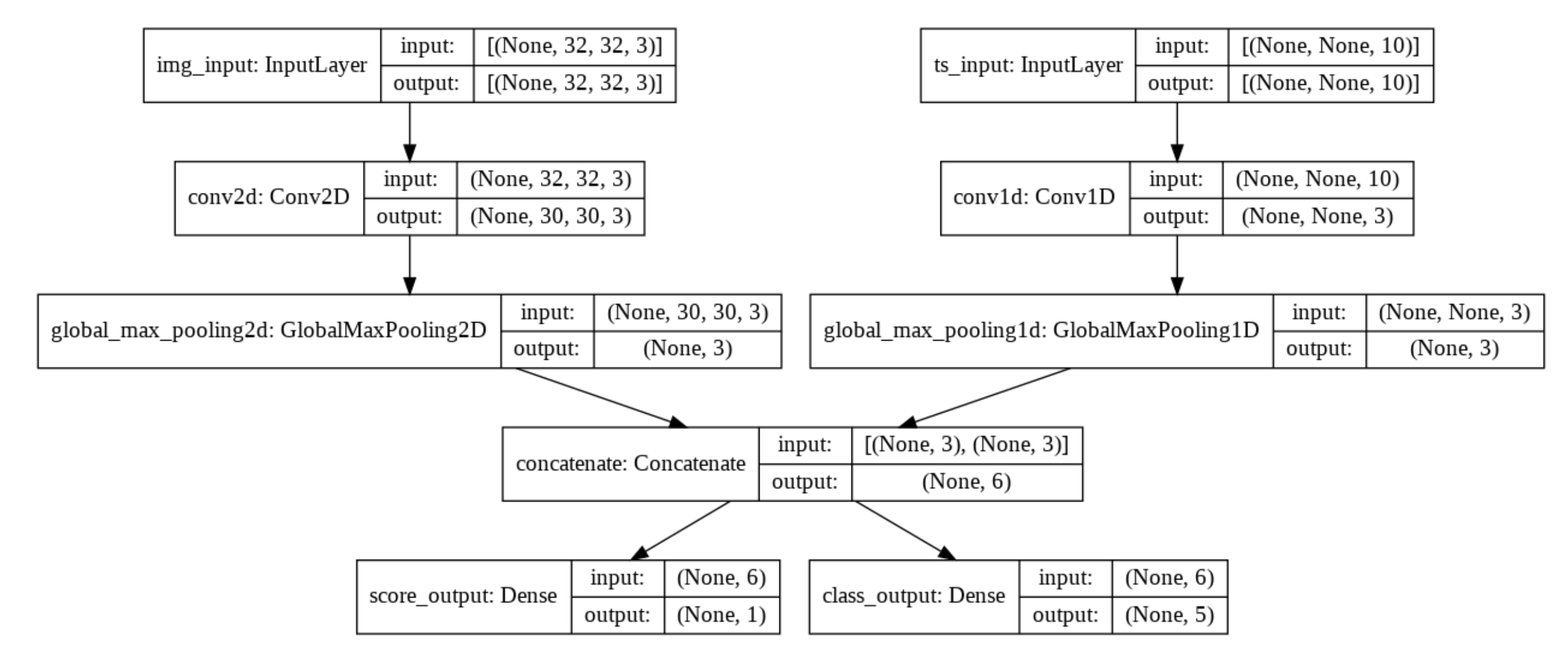
컴파일할 때 loss function에 각 output에 맞는 서로다른 loss에 대한 리스트를 전달할 수 있습니다.
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=[keras.losses.MeanSquaredError(),
keras.losses.CategoricalCrossentropy()])만약 loss fuction을 하나만 전달한다면 모든 output에 대해 동일하게 적용시킵니다.
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=[keras.losses.MeanSquaredError(),
keras.losses.CategoricalCrossentropy()],
metrics=[[keras.metrics.MeanAbsolutePercentageError(),
keras.metrics.MeanAbsoluteError()],
[keras.metrics.CategoricalAccuracy()]])각각에 대해 이름을 지정해주고 싶다면 dict형태로 전달해주면 됩니다.
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss={'score_output': keras.losses.MeanSquaredError(),
'class_output': keras.losses.CategoricalCrossentropy()},
metrics={'score_output': [keras.metrics.MeanAbsolutePercentageError(),
keras.metrics.MeanAbsoluteError()],
'class_output': [keras.metrics.CategoricalAccuracy()]})2가지 이상의 output에 대한 평가지표를 사용할 때 꼭 name을 사용하는 것을 추천합니다.
loss_weight 인수를 사용하여 다른 출력별 손실에 대해 다른 가중치를 부여할 수 있습니다. (예를 들어, 클래스 손실의 2배에 해당하는 중요성을 부여함으로써 우리의 예에서 "점수" 손실을 좀 더 특별하게 하고자 할 수 있습니다).
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss={'score_output': keras.losses.MeanSquaredError(),
'class_output': keras.losses.CategoricalCrossentropy()},
metrics={'score_output': [keras.metrics.MeanAbsolutePercentageError(),
keras.metrics.MeanAbsoluteError()],
'class_output': [keras.metrics.CategoricalAccuracy()]},
loss_weight={'score_output': 2., 'class_output': 1.})이러한 outputs이 예측이아니라 학습을 위한 것이라면, 특정 output에 대해서는 계산을 허용하지 않을 수도 있습니다.
# List loss version
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=[None, keras.losses.CategoricalCrossentropy()])
# Or dict loss version
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss={'class_output': keras.losses.CategoricalCrossentropy()})fit 함수데이터를 적합한 다중 입력 또는 다중 출력 모델로 전송하는 것은 컴파일에서 손실 함수를 지정하는 것과 유사한 방식으로 작동합니다. 넘파이 배열을 활용한 dict나 list형태를 사용할 수 있습니다.
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=[keras.losses.MeanSquaredError(),
keras.losses.CategoricalCrossentropy()])
# Generate dummy Numpy data
img_data = np.random.random_sample(size=(100, 32, 32, 3))
ts_data = np.random.random_sample(size=(100, 20, 10))
score_targets = np.random.random_sample(size=(100, 1))
class_targets = np.random.random_sample(size=(100, 5))
# Fit on lists
model.fit([img_data, ts_data], [score_targets, class_targets],
batch_size=32,
epochs=3)
# Alernatively, fit on dicts
model.fit({'img_input': img_data, 'ts_input': ts_data},
{'score_output': score_targets, 'class_output': class_targets},
batch_size=32,
epochs=3)다음은 DataSet을 이용한 경우입니다.
train_dataset = tf.data.Dataset.from_tensor_slices(
({'img_input': img_data, 'ts_input': ts_data},
{'score_output': score_targets, 'class_output': class_targets}))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
model.fit(train_dataset, epochs=3)'# Machine Learning > TensorFlow doc 정리' 카테고리의 다른 글
| tensorflow 2.0 keras Training and evaluation (4) (0) | 2019.04.12 |
|---|---|
| tensorflow 2.0 keras Training and evaluation (3) (1) | 2019.04.09 |
| tensorflow 2.0 keras Training and evaluation (1) (0) | 2019.04.08 |
| tensorflow 2.0 keras Functional API (2) (0) | 2019.03.30 |
| tensorflow 2.0 keras Functional API (1) (0) | 2019.03.29 |