Abstract
Automatically describing the content of an image is a fundamental problem in artificial intelligence that connects computer vision and natural language processing. In this paper, we present a generative model based on a deep recurrent architecture that combines recent advances in computer vision and machine translation and that can be used to generate natural sentences describing an image. The model is trained to maximize the likelihood of the target description sentence given the training image. Experiments on several datasets show the accuracy of the model and the fluency of the language it learns solely from image descriptions. Our model is often quite accurate, which we verify both qualitatively and quantitatively. For instance, while the current state-of-the-art BLEU-1 score (the higher the better) on the Pascal dataset is 25, our approach yields 59, to be compared to human performance around 69. We also show BLEU-1 score improvements on Flickr30k, from 56 to 66, and on SBU, from 19 to 28. Lastly, on the newly released COCO dataset, we achieve a BLEU-4 of 27.7, which is the current state-of-the-art.
이미지의 내용을 설명하는 것은 컴퓨터 비전과 자연어처리를 연결하는 인공지능의 근본적인 문제이다.
이 논문에서는 컴퓨터 비전과 기계 번역의 최근 발전된 기술을 혼합한 깊은 순환 아키텍쳐에 기반이 되고 있으며 이미지를 설명하는 자연어 문장을 생성가능한 생성 모델을 소개한다.
모델은 주어진 학습이미지를 설명하는 문장을 목표로 liklihood를 최대화하게끔 훈련되어진다.
몇 가지 데이터셋에서의 실험은 모델의 정확성과 이미지 설명으로부터 학습한 언어의 유창성을 보여준다.
본 연구의 모델은 상당히 정확하며 질적, 양적으로 검증되었다.
예를 들면, BLEU-1 score에서 SOTA가 25였다면 우리의 모델은 59나 된다.(인간 69)
우리는 또한 Flickr30k를 사용하여 BLEU-1에서 56 -> 66, SBU 19 -> 28, COCO에서 BLEU-4 27.7을 달성했다.
요약
- 이미지의 설명을 뽑기 위해 첫 부분에서 GoogleNet을 쓰고, 뒤에 LSTM을 이어붙인 구조를 사용하였다.
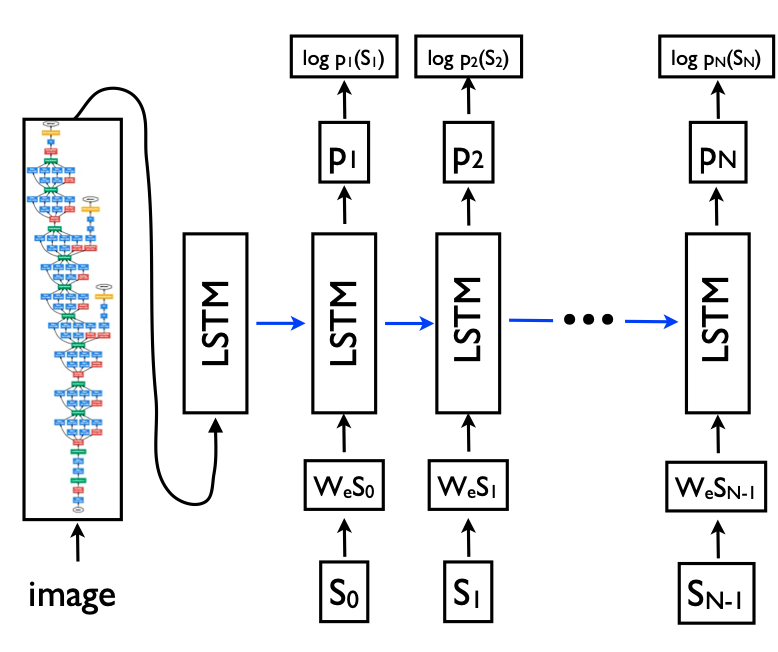
- 모델 구조에서 LSTM으로 이어주기 직전에 이미지 벡터 공간을 워드 벡터 공간으로 매핑시켜주는 레이어를 추가하였다.
- 이 논문은 word2vec의 사용을 강조하고 있다.(시기 상 나온지 얼마 안된 시점)
- 기존에 문장 생성 시에 워드 벡터 공간에서 가장 확률이 높은 단어를 사용하는 샘플링 방법을 사용하는데, 이 논문은 이 방법을 사용하지 않고 BeamSearch 기법을 활용하였다. 이 기법은 k 개(논문에서는 20개)의 후보를 항상 유지하여 가장 마지막 단계에서 후보를 선택함. k를 1로 두는 것보다 20으로 두는게 좀 더 성능이 좋았다. 하지만 높을수록 오버피팅의 문제가 심각하였으며, 이 때문에 실제 대회에서는 3으로 줄여서 사용했다.
- BLEU-n 평가 방식은 문장에서 단어가 몇개나 정확한가를 평가하는 지표인데, 이미지 캡션에서는 잘 맞지 않는 지표일 수 있다. 예를 들어 BLEU-3은 연속적인 3개의 단어가 얼마나 정확한가에 대한 것 뿐만 아니라 1, 2개의 연속적인 단어에 대해서도 확인하는 것이다. n이 증가할 수록 어려워진다.
- 학습 시에 오버피팅이 심했는데 이를 해결하기 위해, CNN 부분은 사전 학습 모델을 사용하고 워드 임베딩 벡터는 초기화하지 않고 사용했더니 더 잘되었다. 추가적으로 드롭아웃과 앙상블을 활용했다.
- 2 단계 학습을 사용했는데, 처음 단계는 Inception 모델의 가중치를 동결시키고 학습시킨 후에 두번째로 Fine-Tune을 수행하였다.
- 논문이 아닌 대회를 위해서 모델에 일정 부분을 변경하여 참여하게 되었는데, 먼저 Fine-Tune 시에 LSTM를 일정 수준까지 학습한 뒤에 CNN의 Fine-Tune을 수행하였다.
Reference
Vinyals, O., Toshev, A., Bengio, S., & Erhan, D. (2015). Show and tell: A neural image caption generator. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3156-3164).
'# Paper Abstract Reading' 카테고리의 다른 글
| Learning Deep Features for Discriminative Localization (0) | 2019.12.22 |
|---|---|
| DeepLab: Semantic Image Segmentation withDeep Convolutional Nets, Atrous Convolution,and Fully Connected CRFs (0) | 2019.12.20 |
| WaveNet - A Generative Model for Raw Audio (0) | 2019.12.07 |
| Learning to Remember Rare Events (0) | 2019.12.02 |
| Understanding Black-box Predictions via Influence Functions (0) | 2019.12.01 |