Abstract
We present a conceptually simple, flexible, and general framework for object instance segmentation. Our approach efficiently detects objects in an image while simultaneously generating a high-quality segmentation mask for each instance. The method, called Mask R-CNN, extends Faster R-CNN by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition. Mask R-CNN is simple to train and adds only a small overhead to Faster R-CNN, running at 5 fps. Moreover, Mask R-CNN is easy to generalize to other tasks, e.g., allowing us to estimate human poses in the same framework. We show top results in all three tracks of the COCO suite of challenges, including instance segmentation, bounding-box object detection, and person keypoint detection. Without tricks, Mask R-CNN outperforms all existing, single-model entries on every task, including the COCO 2016 challenge winners. We hope our simple and effective approach will serve as a solid baseline and help ease future research in instance-level recognition. Code will be made available.
우리는 간단하고 융통적이며 일반적인 객체 사물 분할 프레임워크를 소개한다.
우리의 접근법은 각 인스턴스에 대해 높은 수준의 분할 마스크를 동시다발적으로 생성하여 객체를 효율적으로 탐지한다.
Mask R-CNN은 bbox 인식을 위해 기존 브랜치와 병렬로 객체 마스크를 예측하기 위한 브랜치를 ㅊ누가하여 Faster R-CNN의 개념을 확장한다.
또한, 학습이 쉬우며, 5 fps로 수행되는 Faster R-CNN에 작은 오버헤드만 추가된다.
게다가 동일한 프레임워크에서 사람 포즈를 인식하는 것과 같은 다른 task에 일반화하기 쉽다.
인스턴스 분할 문제가 포함된 COCO 챌린지, bbox 객체 탐지, 사람 특정 포인트 탐지와 같은 3개의 작업에서 모두 최상의 결과를 보여준다.
어떠한 트릭도 없이 Mask R-CNN은 COCO 2016 대회의 우승을 포함하여 모든 task에서 outperform 하였다.
우리는 간단하고 효과적인 접근 방식이 훌륭한 baseline이 되고, 향후 인스턴스 수준의 인식에 대한 연구를 용이하게 하기를 희망한다.
요약
- 이 논문은 Instance Segmentation 문제를 다루고 있는데, 이와 동일한 분야로 bbox를 통한 분류, semantic segmentation이 존재한다. 각가은 객체를 찾을 수 있지만 seg 할 수 없는 문제와 seg를 할 수 있지만 각각의 객체를 분할할 수 없는 단점을 가지고 있다. 하지만 Instance Segmentation은 seg도 할 수 있으면서 객체 분류까지 다뤄보는 문제이다.
- 기존의 방법ㅇ은 clasfication 과 bbox regression 브랜치를 사용하는데, 이 방법은 단순하게 원래의 방법에 더하여서 mask brarnch를 추가한 방법이다. mask branch는 물체가 어떤 물체인지에 대한 판단을 상관하지 않고, 해당 물체의 mask만 학습한다.
- fully connected나 pooling을 사용하면 translation-equivariant가 깨지게 되는데, Faster R-CNN이나 본 논문에서 사용하는 구조는 Fully Convolution Network로 구성되어 있기 때문에 위의 공식이 깨지지 않는다.
- 기존의 Fast R-CNN은 bbox reg, cls를 위해 fully connected를 거치게 되는데, 이를 위해 추론된 모든 field를 동일한 크기로 맞춰주기 위해 ROI pooling을 사용한다. Mask R-CNN은 이와 거의 동일하게 ROI Align을 사용하는데, 일단 기존의 ROI pooling에서 사용되는 크기인 7x7로 통일되는 feaeture의 크기가 너무 작아서 사용한다.
- 또 기존의 ROI pooling은 실수값으로 region pixel을 예측하는데, 이를 대충 자른 후 큰 값을 찾고 이를 통해 공통된 크기로 통일하게 된다. 이때 약간 비대칭적인 또는 정렬되지 않는 문제가 발생한다. 그래서 이를 align하게 가져가기 위해 ROI align을 사용한다.
- ROI align은 field에서 각각의 걸쳐있는 부분의 interpolation을 통해 pixel의 최종 값을 구하게 된다.
- ROI를 할때 zeropadding을 하게 되는데, 그 이유는 학습 과정에서 객체가 겹칠 수 있기 때문이다.
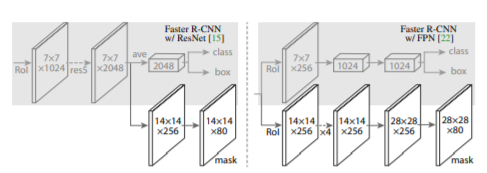
- backbone으로는 ResNet과 FPN 구조를 사용하였다.
Reference
He, K., Gkioxari, G., Dollár, P., & Girshick, R. (2017). Mask r-cnn. In Proceedings of the IEEE international conference on computer vision (pp. 2961-2969).
https://www.youtube.com/watch?v=RtSZALC9DlU&list=PLWKf9beHi3Tg50UoyTe6rIm20sVQOH1br&index=57
'# Paper Abstract Reading' 카테고리의 다른 글
| Deep Neural Networks for YouTube Recommendations (0) | 2020.01.16 |
|---|---|
| Style Transfer from Non-Parallel Text by Cross-Alignment (0) | 2020.01.16 |
| Capsule Network (0) | 2020.01.16 |
| ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices (0) | 2020.01.13 |
| Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization (0) | 2020.01.08 |