ABSTRACT
YouTube represents one of the largest scale and most sophisticated industrial recommendation systems in existence. In this paper, we describe the system at a high level and focus on the dramatic performance improvements brought by deep learning. The paper is split according to the classic two-stage information retrieval dichotomy: first, we detail a deep candidate generation model and then describe a separate deep ranking model. We also provide practical lessons and insights derived from designing, iterating and maintaining a massive recommendation system with enormous userfacing impact.
유튜브는 가장 거대하고 정교한 상업적 추천시스템이다.
이 논문은 높은 수준으로 시스템을 설명하고 딥러닝으로 인한 극적 성능 향상의 설명을 다룬다.
논문은 고전적인 2단계 정보 검색 이분법에 따라 분할하여 설명한다.
첫 번째, 깊은 후보 생성 모델을 자세히 설명하고 별도의 깊은 순위 모델을 설명한다.
또한, 대규모 사용자 추천 시스템을 설계, 반복 및 유지 관리하는 데 도움이 되는 실질적인 교훈과 통찰을 제공한다.
요약
- 크게 두 가지를 사용한다. Candidate Generation Model과 Ranking Model.
- 실제 상황에서는 엄청난 양의 데이터와 제한된 컴퓨팅 파워, 새로운 컨텐츠, 그리고 노이즈 데이터와 같은 문제를 해결해야 한다.
- 전체적인 구조는 다음과 같다.
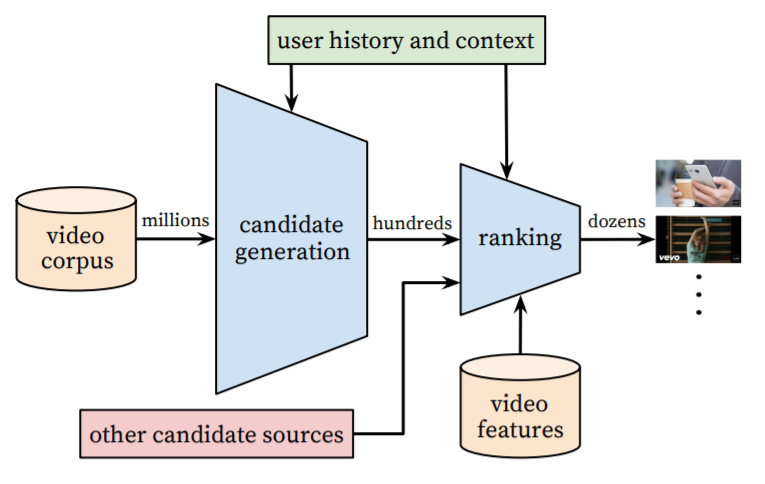
- 수백만개의 비디오를보고 유저 정보를 통해 후보들을 만들어낸다. -> 후보들을 추려내고 비디오 특징을 통해 랭킹을 매겨서 최종적으로 추천을 하게 된다.
< 후보 생성 모델 >
- Video Embedding과 Search Token Embedding을 사용하였고, 모두 Dense Vector를 사용. Embedding 다음으로는 Combiner를 통과하는데, Combiner는 Embedding의 값을 average하여 watch vector와 search vector를 만듬.
- 위에서 만든 2개의 벡터와 Example age, gender 등의 모든 정보를 concat함. 이렇게 만들어진 vector를 fcn에 통과시킴. 모든 단계는 다음 그림과 같다.
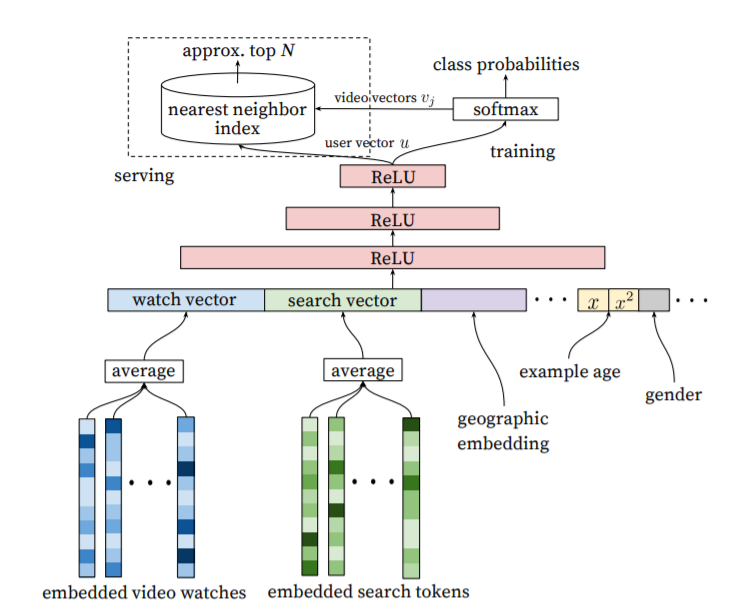
- 출력값은 유저가 어떠한 정보를 선호하는가에 대한 값이며, 이를 softmax로 구함. 하지만 출력값은 몇백만개가 되므로 Negative Sampling을 통해 거르고 난 후의 결과를 사용함.
- 모델 학습이 과거의 동영상을 사용하기 때문에, 실제 추천에서도 과거 동영상을 고르는 경우가 많음. 따라서 이를 방지하기 위해 Example Age, 즉 영상의 나이를 피처로 추가하였음. 특히 이런 피처들을 넣었을 경우 성능 향상을 직접적으로 경험하였다고 실험에서 보여주었음.
- 그 외에 모든 비디오 시청이력을 사용하였고, heavy user에 치우치지 않도록 이용자별 영상 횟수를 fix하고, 새로운 검색 쿼리에 추천엔진을 반영하지 않고, 비대칭적인 감상 패턴을 적용한다. 여기서 비대칭적인 감상 패턴은 A -> B -> C 순서의 동영상 시청처럼 규칙적인 것이 아닌 것을 말한다.
< 랭킹 모델 >
- 동일하게 임베딩을 사용함. 대신 이 모델의 임베딩에서는 average 뿐만 아니라 임베딩 값을 직접 활용하는 등의 계산이 추가되어 있음. 또한, 임베딩 concat에서 여러 가지 특징을 normalize해서 concat 하도록 함.
- 출력값 부분에서는 감상 시간별로 가중치를 주는 방법을 통해 성능을 개선시켰음(weighted logistic reg). 이는 추천된 영상을 얼마나 오랫동안 볼지 예측하는 것을 목표로 하는 것임. 감상 시간은 안봤으면 0, 봤으면 본 시간을 값으로 넣음.
- 이전에는 감상 시간이 아니라 안봤다, 봤다 또는 영상을 클릭했냐 안했냐(0과 1)로 판단하였다고 함. 이를 CTR(Click Through Rate)라고 함.
- 추가로 구글에서는 전통 머신러닝처럼 Feature Engineering을 행하여서 성능 향상을 이루었음. 가장 좋은 feature는 비슷한 비디오에 대한 유저의 반응이라고 함.
Reference
Covington, P., Adams, J., & Sargin, E. (2016, September). Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM conference on recommender systems (pp. 191-198). ACM.
https://www.youtube.com/watch?v=V6zixdCIOqw&list=PLWKf9beHi3Tg50UoyTe6rIm20sVQOH1br&index=60
'# Paper Abstract Reading' 카테고리의 다른 글
| DEEP COMPRESSION: COMPRESSING DEEP NEURALNETWORKS WITH PRUNING, TRAINED QUANTIZATIONAND HUFFMAN CODING (1) | 2020.01.29 |
|---|---|
| Efficient Neural Architecture Search via Parameter Sharing (0) | 2020.01.24 |
| Style Transfer from Non-Parallel Text by Cross-Alignment (0) | 2020.01.16 |
| Mask R-CNN (0) | 2020.01.16 |
| Capsule Network (0) | 2020.01.16 |