https://www.youtube.com/watch?v=n7byMbl2VUQ&list=PLQY2H8rRoyvzuJw20FG82Lgm2SZjTdIXU&index=8
머신러닝 프로세스는 크게 두 가지로 설명할 수 있습니다.
- 데이터 전처리
- 모델을 통한 연산
전처리 과정에서 우리는 CPU를 활용해서 이미지를 cropping한다던지, 기타 video 영상을 위한 처리 등을 수행합니다.
만약 전체 트레이닝 속도가 느리다면, 위 두 가지 과정 중 하나가 bottleneck일 것입니다.
GPU나 TPU는 계속해서 엄청나게 발전해왔습니다.
이들은 Matrix, linear algebra 등의 연산을 매우 빠르게 수행함으로써 ML의 속도를 향상시켰습니다.
하지만 CPU는 GPU에 비해 상대적으로 그렇게 향상되지 못했습니다.
만약 데이터 전처리 과정에서 병목 현상이 발생한다면 전체 과정이 매우 느려질 것입니다.
그래서 이번 영상에서는 tf.data를 활용하여 속도를 개선시키는 방법을 살펴볼 것입니다.
먼저, tf.data는 다들 알다시피 데이터 전처리를 위한 쉽고, 유용한 프레임워크입니다. 아래 코드에서 tf.data의 대략적인 프로세스를 볼 수 있습니다.
import tensorflow as tf
def expensive_preprocessing(record):
pass
dataset = tf.data.TFRecordDataset('.../*.tfrecord')
dataset = dataset.map(expensive_preprocessing)
dataset = dataset.shuffle(buffer_size = 1024)
dataset = dataset.batch(batch_size = 128)
dataset = dataset.prefetch()
model = tf.keras.Mpdel(...)
model.fit(dataset)- Dataset 객체를 생성하고,
- 일련의 preprocessing 함수를 적용하고,
- shuffle과 batch를 결정하고,
- prefetch() 옵션을 넣어줍니다. prefetch()는 데이터의 입력 과정에서 다음 큐에 들어갈 데이터의 전처리를 미리 병렬적으로 수행하는 함수입니다.
- 마지막으로 모델을 학습시킵니다.
그렇다면 데이터 전처리의 병목 현상을 해결할 수 있는 방법은 무엇이 있을까요?
첫 번째 아이디어는 reuse computation입니다.
이 방법은 우리가 수행하는 전처리 과정에서의 연산을 한번만 사용하지 말고, 저장해두었다가 다음 연산에서도 다시 사용하는 것을 의미합니다.(약간 캐시와 비슷한 느낌?)
이 방법을 수행할 수 있도록 tf.data snapshot을 소개합니다. 데이터 전처리 과정을 저장해두었다가 사용할 수만 있다면, 모델 아키텍처를 실험하거나 여러 가지 하이퍼파라미터를 실험하는 데에 있어서 매우 유용할 것입니다.
snapshot 기능은 다음과 같이 사용할 수 있습니다.
import tensorflow as tf
def expensive_preprocessing(record):
pass
dataset = tf.data.TFRecordDataset('.../*.tfrecord')
dataset = dataset.map(expensive_preprocessing)
dataset = dataset.snapshot("/path/to/snapshot_dir/") # add
dataset = dataset.shuffle(buffer_size = 1024)
dataset = dataset.batch(batch_size = 128)
dataset = dataset.prefetch()
model = tf.keras.Mpdel(...)
model.fit(dataset)- snapshot 기능을 사용하면 일단 한번은 전체 디스크를 활용하지만, 다음 연산부터는 이를 참고하여 연산을 수행할 수 있습니다.
- 그리고 snapshot은 shuffle 기능을 사용하기 전에 추가해두어야 합니다. 셔플 후에 사용하면 모든 작업이 frozen되기 때문에 주의해야 합니다. 랜덤하게 입력하는 장점을 사용할 수 없죠.
또, 이 기능은 TF 2.3부터 이용가능하다는군요.
두 번째 아이디어는 distribute computation입니다.
이 방법은 Host CPU를 만들어 worker들에게 작업을 할당한 뒤 병렬적으로 처리하고 결과는 Host CPU에서 종합하도록 합니다.
이를 tf.data serveice로 제공합니다.
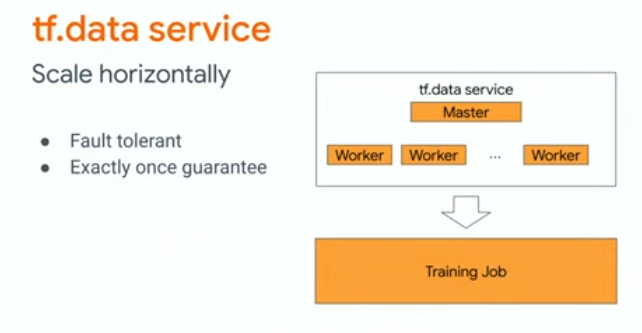
사용 방법은 코드로 확인할 수 있습니다.
import tensorflow as tf
def randomized_preprocessing(record):
pass
dataset = tf.data.TFRecordDataset('.../*.tfrecord')
dataset = dataset.map(randomized_preprocessing)
dataset = dataset.shuffle(buffer_size = 1024)
dataset = dataset.batch(batch_size = 32)
dataset = dataset.distribute("<master_address>") # add
dataset = dataset.prefetch()
model = tf.keras.Model(...)
model.fit(dataset)- distribute 이전의 코드는 cluster에서 셋팅한 worker들이 병렬적으로 수행합니다.
'# Machine Learning > TensorFlow video 정리' 카테고리의 다른 글
| TF Dev Summit 2020 훑어보기(Research with TensorFlow) (0) | 2020.03.18 |
|---|---|
| TF Dev Summit 2020 훑어보기(TensorBoard dev.) (0) | 2020.03.17 |
| TF Dev Summit 2020 훑어보기(TensorFlow Hub) (0) | 2020.03.16 |
| TF Dev Summit 2020 훑어보기(Learning to read with TensorFlow and Keras) (0) | 2020.03.15 |
| TF Dev Summit 2020 훑어보기(Keynote) (0) | 2020.03.15 |