GoogLeNet 즉, 구글에서 발표한 Inception 계통의 Network에서는 1x1 Convolution을 통해 유의미하게 연산량을 줄였습니다. 그리고 이후 Xception, Squeeze, Mobile 등 다양한 모델에서도 연산량 감소를 위해 이 방법을 적극적으로 채택하고 있습니다. 뿐만 아니라 Semantic Segmentation 연구에서도 채널(Channel) 또는 공간적(Spatial) 특성 파악을 위해 1x1 Convolution 방법 사용이 유의미하다는 것을 증명한 바 있습니다.
깊이 들어가지 않더라도 Image Classification Task에서 모델 구조를 개발한 몇 가지 논문만 살펴보아도 이러한 장점을 단번에 알아볼 수 있습니다.
이번 글에서는 1x1 Convolution을 쉽게 설명해보았습니다. 1x1 Convolution은 직관적으로 1x1 크기를 가지는 Convolution Filter를 사용한 Convolution Layer입니다.
1x1 Convolution에는 크게 세 가지 장점이 있다고 말할 수 있습니다.
- Channel 수 조절
- 연산량 감소(Efficient)
- 비선형성(Non-linearity)
1. Channel 수 조절
Convolution Layer를 사용해서 Custom Model을 구성할 경우, Channel 수는 하이퍼파라미터이기 때문에 우리가 직접 결정해주어야 합니다. 대부분은 논문을 참조하지만, 그렇지 않은 경우는 특성에 맞게 우리가 직접 결정해주어야 합니다.
이 부분에서 1x1 Conv의 장점을 알 수 있습니다. Channel 수는 우리가 원하는만큼 결정할 수 있습니다. 하지만 컨볼루션 연산에서 특히 충분히 큰 크기의 Channel 수를 사용하고자 할때 문제가 되곤 합니다. 왜냐하면 그만큼 파라미터 수가 급격히 증가하기 때문이죠. 하지만 1x1 Convolution을 사용하면 효율적으로 모델을 구성함과 동시에 만족할만한 성능을 얻을 수 있습니다.
파라미터 수가 급격하게 증가하는 것을 예방하기 때문에 Channel 수를 특정 경우가 아닌 이상 마음껏 조절할 수 있고, 다양한 크기를 가진 Convolution Layer를 통해 우리가 원하는 구조의 모델을 구성해볼 수 있습니다.
밑의 그림에서는 이와 같이 1x1x128 Convolution을 활용하여 우리가 원하는 수의 Channel 수를 가지는 층을 구성하고 있습니다.
2. 계산량 감소
* 여기서 파라미터 수는 주로 결과값 크기를 의미합니다. 밑 그림에서 (28*28)을 제거해야 진정한 의미의 파라미터 수라고 말할 수 있습니다. 하지만 편의를 위해 파라미터 수라고 언급하겠습니다. 유의하시길 바랍니다.
* 아래 입력의 크기는 Conv(padding = 'same') 전제하에 계산해주세요.
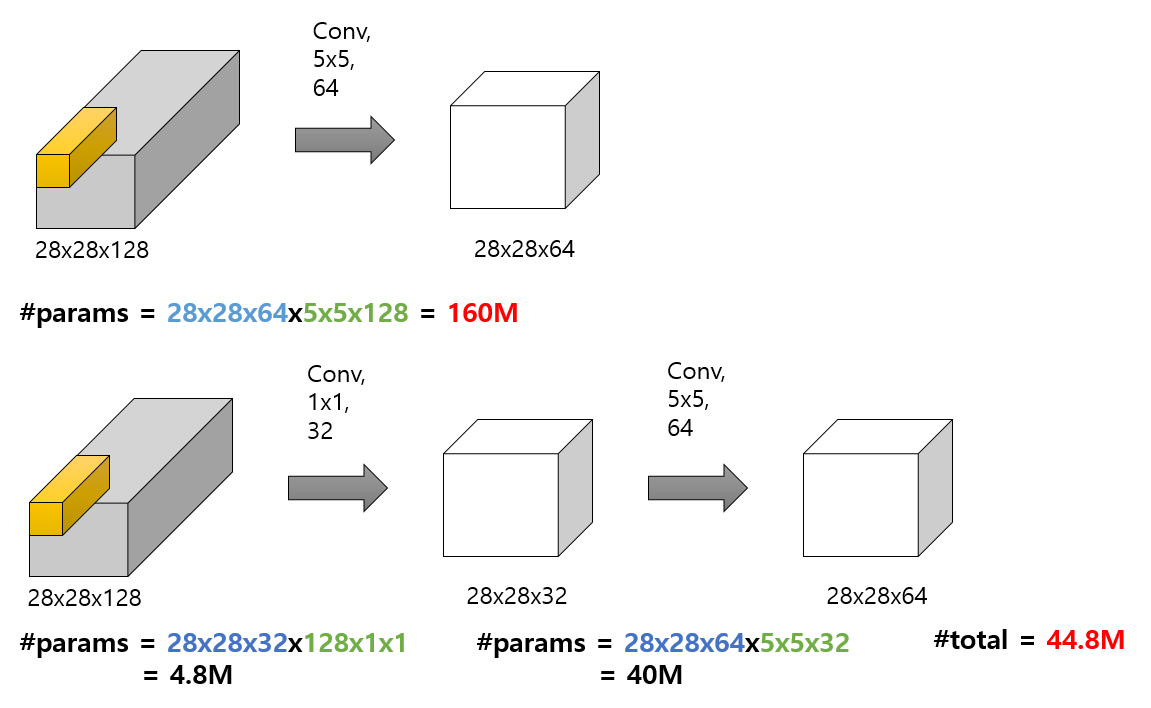
위 그림처럼 Channel 수 조절은 계산량 감소에 직접적으로 영향을 주게 되어 네트워크를 구성할 때 좀 더 깊게 구성할 수 있도록 도움을 줍니다. 여기서 Channel 수를 줄였다가 다시 늘이는 부분을 Bottleneck 구조라고 표현하기도 합니다. 파라미터 수가 많으면 아무리 보유하고 있는 GPU나 RAM이 좋아도 감당하기 힘드니 우리 입장에선 적극 고려해볼만한 방법입니다.
위 그림을 보면, 위와 아래 예시의 차이는 1x1 컨볼루션 사용 유무입니다.
- 빨간색 글씨는 해당 과정에서 사용되는 전체 파라미터 개수를 의미합니다. 윗 부분은 160백만개의 파라미터 수가 필요하고, 아랫 부분은 약 44백만개의 수가 필요하네요. 대략 4배의 차이입니다. 이처럼 1x1 컨볼루션을 사용하면, 사용 유무에 따라 모델 파라미터 수가 급격하게 차이가 납니다.
- 초록색 글씨는 컨볼루션 필터가 가지는 파라미터 수입니다.
- 파란색 글씨는 필터 크기(또는 갯수)를 나타내며, 초록색 글씨와 곱해 최종 파라미터 수를 구하게 됩니다.
(28*28은 파라미터가 아니므로 무시해도 무관하나, 여기서는 계산 편의와 직관을 위해 포함합니다.)
따라서, 위 예시의 (28 * 28 * 64 * 5 * 5 * 128)을 해석하면, (5 * 5 * 128) 크기의 컨볼루션 필터가 64개 사용되어 최종적으로 (28, 28, 64) 크기를 가지는 결과물이 나온다는 것입니다.
예시를 통해 각 숫자가 나타내는 의미가 무엇인지 생각해보시기 바랍니다. 만약 정확히 떠오르지 않는다면, 아직 컨볼루션 연산 개념이 정확히 확립되지 않은 것일 수 있습니다.
Convolution Layer는 굉장히 자주 사용하기 때문에 개념을 정확히 알고 넘어가는 것이 큰 도움이 될 수 있습니다.
3. 비선형성
GoogLeNet을 포함하여 구글팀의 수많은 고민이 포함되어 적용된 Inception 계통의 다양한 model version을 공부하면, 많은 수의 1x1 Conv를 사용했다는 것을 알 수 있습니다. 이때 ReLU Activation을 지속적으로 사용하여 모델 비선형성을 증가시켜 줍니다. ReLU 사용 목적 중 하나는 모델의 비선형성을 더해주기 위함도 있습니다. 비선형성이 증가한다는 것은 그만큼 복잡한 패턴을 좀 더 잘 인식할 수 있게 된다는 의미와 비슷하겠죠?
1x1 Convolution을 사용하면서 사용되는 파라미터 수가 감소하게 되고, 이러한 이점을 통해 모델을 더욱 깊게 구성할 수 있습니다. 모델을 깊게 구성하는 과정에서 기존보다 많은 수의 비선형성 활성화 함수를 사용하게 되고, 모델은 점점 더 구체적인 패턴을 파악할 수 있어 성능 향상을 이룰 수 있겠죠?
'# Machine Learning > 글 공부' 카테고리의 다른 글
| FR(face recognition)의 과거부터 현재까지의 동향이 궁금하다면? (0) | 2018.12.26 |
|---|---|
| deconvolution(conv2Dtranspose) vs upsampling (0) | 2018.12.10 |
| basic gradient(+backprop) with numpy (0) | 2018.12.09 |
| Logistic Regression 의 비용함수 (0) | 2018.12.09 |
| Multi Class vs Multi Label (0) | 2018.12.06 |