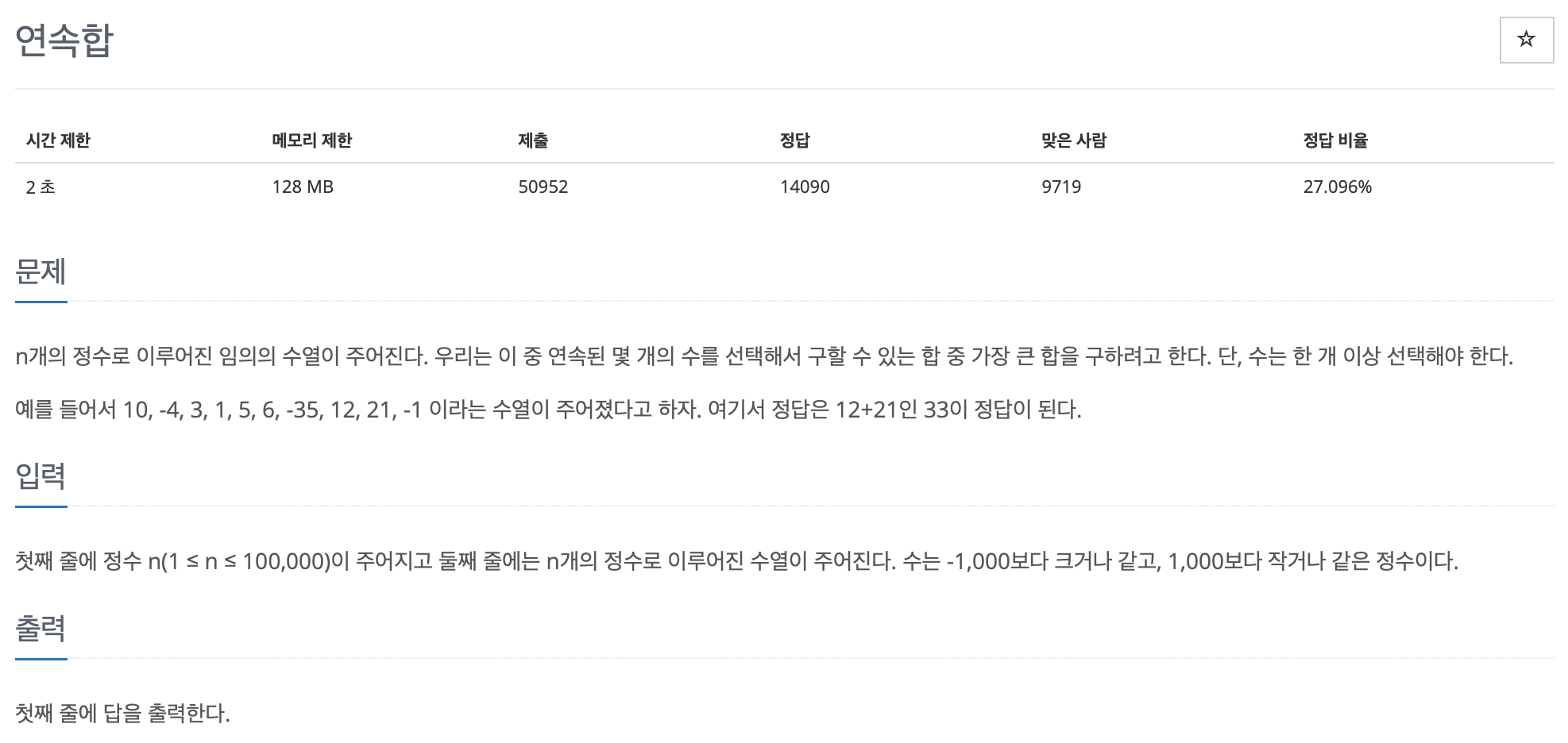
먼저 깃허브 저장소를 가장 따라하기 쉽게 설명해놓은 것은 이미 git에서 만들어 놓았다.
깃허브에서 new repogitory를 만들고 README를 initialize하지 않은채로 생성하면,
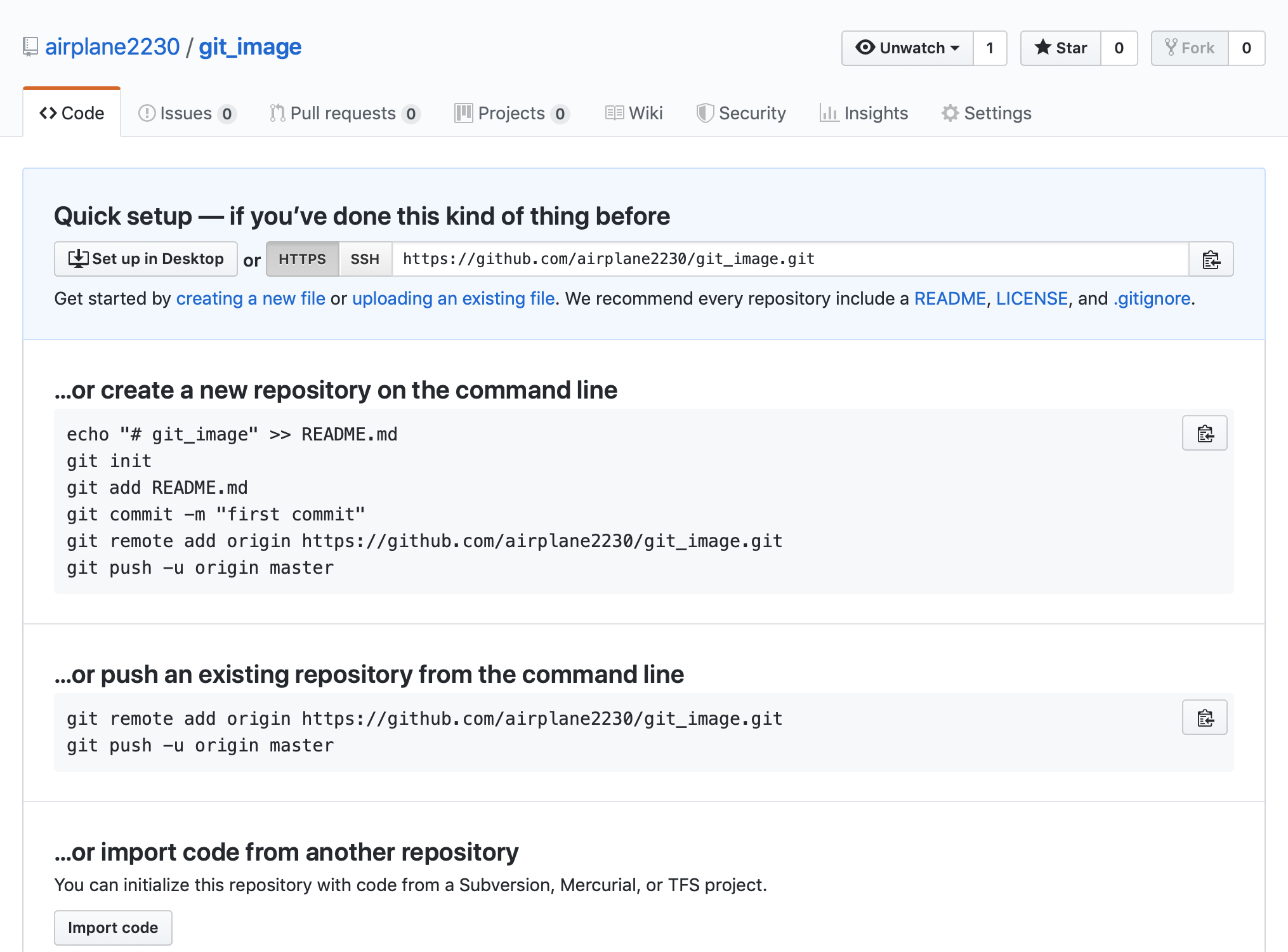
다음과 같이 페이지가 뜨게되는데, 회색 코드블럭에 있는 것을 따라하면 생성할 수 있다.
깃 저장소를 remote한 상태라면 파일을 업데이트하기 위해서는 대부분 다음과 같은 순서를 따른다.
1. git add *.py (파이썬 파일만 업데이트 할 경우)
2. git status
- add에서 추가한 파일의 상태가 나오게 된다. 만약 status에 원하는 파일이름이 없다면 다시 add를 해주어야한다.
- 또한, git을 commit하기 전에 파일을 수정했다면, 다시 add해주어야 한다.
3. git commit -m message
- add한 파일들에 대해 commit을 진행하여 본격적으로 깃 저장소에 업데이트할 수 있는 상태가 됩니다.
- message는 해당 commit에 대한 설명을 적어줍니다.
4. git push -u origin master
- push는 마지막으로 commit한 파일들을 깃 저장소에 업데이트 하겠다는 의미입니다.
5. git pull
- 저장소의 내용을 전부 받아옵니다.
6. git clone git주소
- 해당 git 주소를 복제합니다.
7. git branch [브랜치 이름]
- 새로운 브랜치를 만듭니다.
8. git checkout [브랜치 이름]
- 해당 브랜치로 이동합니다.
등등...
'# 기타 공부한 것들 > git' 카테고리의 다른 글
| .gitignore를 활용해서 원하지 않는 파일 push 안하기 (0) | 2020.07.03 |
|---|---|
| 깃허브 저장소에 100MB 이상의 대용량 파일 업로드 하기 (0) | 2020.01.15 |
| git alias 사용하기 (0) | 2019.09.23 |
| jekyll을 활용하여 git blog 만들어보기 (1) | 2019.09.23 |
| Git, 기본부터 공부하기에 좋은 곳 (0) | 2019.09.08 |