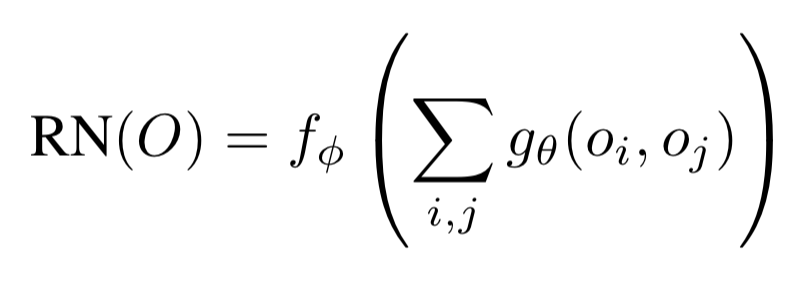Abstract
Rectified activation units (rectifiers) are essential for state-of-the-art neural networks. In this work, we study rectifier neural networks for image classification from two aspects. First, we propose a Parametric Rectified Linear Unit (PReLU) that generalizes the traditional rectified unit. PReLU improves model fitting with nearly zero extra computational cost and little overfitting risk. Second, we derive a robust initialization method that particularly considers the rectifier nonlinearities. This method enables us to train extremely deep rectified models directly from scratch and to investigate deeper or wider network architectures. Based on the learnable activation and advanced initialization, we achieve 4.94% top-5 test error on the ImageNet 2012 classification dataset. This is a 26% relative improvement over the ILSVRC 2014 winner (GoogLeNet, 6.66% [33]). To our knowledge, our result is the first1 to surpass the reported human-level performance (5.1%, [26]) on this dataset.
정류한 활성화 유닛은 최고 성능의 신경망에서 필수적으로 사용된다.
이 논문에서는 두 가지 관점의 이미지 분류에서 rectifier neural network에 대해 연구했다.
첫번째로, 기존에 사용하던 rectified unit을 일반화한 PReLU를 제안한다.
PReLU는 오버피팅의 위험이 적고, 추가 계산 비용이 들지 않게끔 모델을 향상시킨다.
두번째로, 특히 rectifier 비선형성을 고려한 견고한 초기화 방법을 제안한다.
이 방법은 네트워크 구조를 깊게 또는 넓게 사용하게 해주고, 초기 모델에서부터 깊게 구성하여 학습시킬 수 있게 한다.
학습 가능한 활성화 함수와 향상된 초기화에 기반하여, 우리는 2012 ImageNet 분류 데이터셋에서 top-5 test error 4.94%를 달성했다.
이는 ILSVRC2014 우승자에 비해 상대적으로 26%의 향상을 이끌었다는 의미이다.
위의 결과는 2012 ImageNet 데이터셋에서 인간 수준의 성능을 첫번째로 뛰어넘은 것이다.
요약
- Relu를 parametric하게 변화시킨 점과 Relu에 맞게 가중치를 초기화하는 방법
- 기본 Relu보다는 성능이 좋았다. 특징으로는 밑의 첫번째 그림에서 a가 학습 가능한 변수인데, CNN이 깊어지도록 작은 값을 가진다는 것
- Relu의 특성을 이용하여 normal distribution을 구한 것이 kaiming init이다.
- Relu를 사용할 떄, Xavier보다 더 좋은 성능이 나왔다.
- 기존 활성화 함수보다 100% 좋은 점은 아니다(다른 연구자들의 사견, 논문 내용은 아님)
- 하지만 이 이후에 Batch-Normalization이 나오면서 성능면에서 바로 뒤쳐진 논문...?


Reference
He, K., Zhang, X., Ren, S., & Sun, J. (2015). Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE international conference on computer vision (pp. 1026-1034).
'# Paper Abstract Reading' 카테고리의 다른 글
| Pixel Recurrent Neural Network (0) | 2019.09.23 |
|---|---|
| YOLO9000: Better, Faster, Stronger (2) | 2019.09.21 |
| A Simple Neural Network Module for Relational Reasoning (0) | 2019.09.17 |
| Infogan: Interpretable representation learning by information maximizing generative adversaial nets. (0) | 2019.09.15 |
| SSD : Single Shot MultiBox Detector (0) | 2019.08.12 |