Dataset.map(f)는 입력 데이터셋의 각 원소에 주어진 함수 f를 적용하여 새로운 데이터셋을 생성해줍니다. 함수형 프로그래밍 언어에서 리스트 또는 기타 구조에 적용되는 map() 함수를 기반으로 합니다. 함수 f는 입력에서 단일 요소인 tf.Tensor 오브젝트를 받으며, 새로운 데이터셋에 포함될 tf.Tensor 오브젝트를 반환합니다. 이에 대한 구현은 TensorFlow 연산을 사용하여 한 요소를 다른 요소로 변환합니다.
이번 절에서는 Dataset.map()의 사용 방법을 다룹니다.
Decoding image data and resizing it
실제 환경의 이미지 데이터를 학습시킬 때, 보통 서로 다른 크기의 이미지를 공통 크기로 변환하여 고정 크기의 배치를 사용합니다. flower 데이터셋을 사용해봅시다.
# Reads an image from a file, decodes it into a dense tensor, and resizes it
# to a fixed shape.
def parse_image(filename):
parts = tf.strings.split(filename, '/')
label = parts[-2]
image = tf.io.read_file(filename)
image = tf.image.decode_jpeg(image)
image = tf.image.convert_image_dtype(image, tf.float32)
image = tf.image.resize(image, [128, 128])
return image, label
images_ds = list_ds.map(parse_image)
for image, label in images_ds.take(2):
show(image, label)
Applying arbitrary Python logic
데이터 전처리 작업에 TensorFlow 연산을 사용하면 성능적으로 이득을 볼 수 있습니다. 하지만 가끔은 입력 데이터를 처리하기 위해 파이썬 라이브러리 함수가 유용할 때가 있습니다. 이를 위해 Dataset.map()에서 tf.py_function()을 사용하세요.
예를 들어, random rotation 처리를 적용하고 싶지만 TensorFlow 연산은 tf.image의 tf.image.rot90 함수만 제공하기 때문에 유용하지 않을 수 있습니다. tf.py_function()을 경험해보기 위해, scipy.ndimage.rotate 함수를 사용해보죠.
또는, dense한 prediction을 원할 경우, feature와 label을 한 단계씩 이동(shift)할 수 있습니다.
def dense_1_step(batch):
# Shift features and labels one step relative to each other.
return batch[:-1], batch[1:]
predict_dense_1_step = batches.map(dense_1_step)
for features, label in predict_dense_1_step.take(3):
print(features.numpy(), " => ", label.numpy())
batches = range_ds.batch(15, drop_remainder=True)
def label_next_5_steps(batch):
return (batch[:-5], # Take the first 5 steps
batch[-5:]) # take the remainder
predict_5_steps = batches.map(label_next_5_steps)
for features, label in predict_5_steps.take(3):
print(features.numpy(), " => ", label.numpy())
데이터셋은 15 배치 크기를 가집니다. label_next_5_steps에서 batch[:-5]는 학습 데이터로 0~9까지 10개, batch[-5:]는 레이블로 10~14까지 5개를 반환합니다.
windows는 [0, 1, 2, 3, 4] --> [1, 2, 3, 4, 5] --> [2, 3, 4, 5, 6] --> ... 과 같이 데이터를 반환합니다.
거의 모든 경우에서, dataset의 첫 단계로 .batch를 사용할 것입니다.
def sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
for example in windows.flat_map(sub_to_batch).take(5):
print(example.numpy())
creditcard_ds = tf.data.experimental.make_csv_dataset(
csv_path, batch_size=1024, label_name="Class",
# Set the column types: 30 floats and an int.
column_defaults=[float()]*30+[int()])
먼저, rejection resampling은 리샘플링에서도 자주 사용되는 방법입니다. 이에 대해 관심이 있다면, 직접 검색하여 공부하는 것도 나쁘지 않습니다.
experimental.sample_from_datasets의 문제점은 클래스마다 별도의 tf.data.Dataset가 필요하다는 것입니다. Dataset.filter를 사용하면 해결할 수 있지만, 데이터를 두배로 로드하는 결과를 초래합니다.
data.experimental.rejection_resample 함수는 dataset 한 번만 로드하여 균형잡힌 결과를 얻을 수 있게 도와줍니다. 밸런스를 위해 이에 위반하는 요소는 제거됩니다. data.experimental.rejection_resample에서 class_func 인자를 사용합니다. class_func 인자는 각 dataset의 요소에 적용되며, 밸런싱을 위해 어떤 클래스에 속하는지를 결정합니다.
creditcard_ds의 요소는 (features, label) 쌍으로 이루어져 있습니다. class_func는 해당 레이블을 반환합니다.
def class_func(features, label):
return label
resampler는 target distribution을 필요로 하며, 선택적으로 initial distribution 추정을 필요로 합니다.
가장 간단한 형태의 배치는 단일 원소를 n개만큼 쌓는 것입니다. Dataset.batch() 변환은 정확히 이 작업을 수행하는데, tf.stack() 연산자와 거의 동일하게 작동합니다. 예를 들면, 각 구성 요소가 가지는 모든 원소는 전부 동일한 shape을 가져야 합니다.
inc_dataset = tf.data.Dataset.range(100)
dec_dataset = tf.data.Dataset.range(0, -100, -1)
dataset = tf.data.Dataset.zip((inc_dataset, dec_dataset))
batched_dataset = dataset.batch(4)
for batch in batched_dataset.take(4):
print([arr.numpy() for arr in batch])
위의 예제에서는 전부 같은 shape의 데이터를 사용했습니다. 그러나 많은 모델(e.g. sequence models)에서 요구되는 입력의 크기는 매우 다양할 수 있습니다(sequence data의 length는 일정하지 않습니다). 이러한 경우를 다루기 위해, Dataset.padded_batch 변환은 패딩을 사용하여 다른 크기의 배치를 사용할 수 있게 도와줍니다.
dataset = tf.data.Dataset.range(100)
dataset = dataset.map(lambda x: tf.fill([tf.cast(x, tf.int32)], x))
dataset = dataset.padded_batch(4, padded_shapes=(None,))
for batch in dataset.take(2):
print(batch.numpy())
print()
def plot_batch_sizes(ds):
batch_sizes = [batch.shape[0] for batch in ds]
plt.bar(range(len(batch_sizes)), batch_sizes)
plt.xlabel('Batch number')
plt.ylabel('Batch size')
아무런 인자를 제공하지 않고, Dataset.repeat()을 사용하면 input을 무한히 반복합니다.
Dataset.repeat은 한 에폭의 끝과 다음 에폭의 시작에 상관없이 인자만큼 반복합니다. 이 때문에 Dataset.repeat 후에 적용된 Dataset.batch는 에폭과 에폭간의 경계를 망각한 채, 데이터를 생성합니다. 이는 이번 예제가 아닌 다음 예제를 보면 이해할 수 있습니다. epoch간의 경계가 없습니다.
만약 각 에폭의 끝에서 사용자 정의 연산(예를 들면, 통계적 수집)을 사용하고 싶다면, 각 에폭에서 데이터셋 반복을 restart하는 것이 가장 단순합니다.
epochs = 3
dataset = titanic_lines.batch(128)
for epoch in range(epochs):
for batch in dataset:
print(batch.shape)
print("End of epoch: ", epoch)
(128,) (128,) (128,) (128,) (116,) End of epoch: 0 (128,) (128,) (128,) (128,) (116,) End of epoch: 1 (128,) (128,) (128,) (128,) (116,) End of epoch: 2
Randomly shuffling input data
Dataset.shuffle()은 고정 크기의 버퍼를 유지하면서, 해당 버퍼에서 다음 요소를 무작위로 선택합니다.
Dataset.shuffle은 셔플 버퍼가 빌 때까지 에폭의 끝에 대한 정보를 알려주지 않습니다. repeat 전에 shuffle을 사용하면 다음으로 넘어가기 전에 한 에폭의 원소를 전부 확인할 수 있습니다.
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.shuffle(buffer_size=100).batch(10).repeat(2)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(60).take(5):
print(n.numpy())
shuffle_repeat = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.ylabel("Mean item ID")
plt.legend()
shuffle 전에 repeat을 사용하면 epoch의 경계가 무너집니다.
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.repeat(2).shuffle(buffer_size=100).batch(10)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(55).take(15):
print(n.numpy())
repeat_shuffle = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.plot(repeat_shuffle, label="repeat().shuffle()")
plt.ylabel("Mean item ID")
plt.legend()
In this article we focus on two supervised visual reasoning tasks whose labels encode a semantic relational rule between two or more objects in an image: the MNIST Parity task and the colorized Pentomino task. The objects in the images undergo random translation, scaling, rotation and coloring transformations. Thus these tasks involve invariant relational reasoning. We observed uneven performance of various deep convolutional neural network (CNN) models on these two tasks. For the MNIST Parity task, we report that the VGG19 model soundly outperforms a family of ResNet models. Moreover, the family of ResNet models exhibits a general sensitivity to random initialization for the MNIST Parity task. For the colorized Pentomino task, now both the VGG19 and ResNet models exhibit sluggish optimization and very poor test generalization, hovering around 30% test error. The CNN models we tested all learn hierarchies of fully distributed features and thus encode the distributed representation prior. We are motivated by a hypothesis from cognitive neuroscience which posits that the human visual cortex is modularized (as opposed to fully distributed), and that this modularity allows the visual cortex to learn higher order invariances. To this end, we consider a modularized variant of the ResNet model, referred to as a Residual Mixture Network (ResMixNet) which employs a mixture-of-experts architecture to interleave distributed representations with more specialized, modular representations. We show that very shallow ResMixNets are capable of learning each of the two tasks well, attaining less than 2% and 1% test error on the MNIST Parity and the colorized Pentomino tasks respectively. Most importantly, the ResMixNet models are extremely parameter efficient: generalizing better than various non-modular CNNs that have over 10x the number of parameters. These experimental results support the hypothesis that modularity is a robust prior for learning invariant relational reasoning.
이번 논문에서는 두 가지 이상의 객체에서 의미적 relational rule을 레이블로 인코딩하는 supervised visual reasoning 작업인 MNIST Parity, Colorized Pentomino에 대해 다룬다.
이미지에서의 각 객체는 회전, 크기, 색 변환이 랜덤하게 이루어진다.
이러한 작업들은 invariant relational reasoning이 포함된다.
두 가지 작업에서 CNN의 고르지 않으며, 다양한 성능을 발견했다.
MNIST Parity 작업에서는 VGG19 모델이 ResNet모델보다 우수한 성능을 보여주었다.
또한, ResNet 계열은 MNIST Parity 작업의 랜덤 초기화에서 민감하게 반응한다.
Colorized Pentomino 작업의 경우, VGG19와 ResNet 모두 최적화가 느리고 일반화가 약하며 약 30%의 테스트 오류를 보여준다.
우리가 테스트한 CNN 모델은 모두 완전히 분산된 계층적 구조를 학습하고, 이러한 표현을 인코딩합니다.
우리는 인간의 시각 피질이 모듈화되고(완전히 분배되는 것과 대조해서), 이는 더 높은 수준의 invariance를 배울 수 있다고 인식하는 신경 과학의 가설에서 시작한다.
ResMixNet 모델을 제안한다. 이는 mixture-of-experts를 통해 더욱 특화되고, 모듈화된 표현을 동시에 사용할 수 있다.
우리는 매우 얕은 ResMixNet이 두 작업에서 각각 2%, 1%의 테스트 오류를 보여주며, 매우 잘 학습할 수 있다는 것을 확인했다.
더욱 중요한 것은, ResMixNet은 매우 효율적인 수의 파라미터를 가진다: 10배가 넘는 매개변수를 가진 모듈화되지 않은 CNN보다 더 좋다.
이러한 실험적 결과는 invariant relational reasoning를 학습하기 위해 모듈화가 중요한 요소라는 것을 보여준다.
요약
기존의 CNN은 discriminative한 표현을 잘 학습하지만, i.i.d.의 조건때문에 adversarial한 공격에 취약하다.
주요한 CNN은 분산된 feature를 계층적으로 매우 잘 학습할 수 있다. 이번 논문에서는 invariant relational rule을 살펴보기 위해 두 가지 데이터셋을 사용한다.
먼저, MNIST Parity Dataset은 (64, 64)의 크기로 해당 이미지에 크기, 회전, 색깔을 랜덤으로 하여 숫자가 그려지게 된다. 이미지에 포함된 숫자가 만약 짝수이거나 홀수일 때, 같은 짝수(홀수)이면 1, 다르면 0을 레이블로 할당한다.
Colorized Pentomino Dataset은 동일하게 (64, 64)로 다음 그림과 같이 랜덤하게 그림을 생성한다. 만약 이미지에 포함된 도형의 모양이 같으면 0, 다르면 1을 레이블로 할당한다.
두 가지 작업의 차이점은 MNIST는 curve한 특성이 있지만, Pentomino 같은 경우는 완전히 사각형의 특징만 가지고 있으며, 둘의 레이블은 각각 AND gate와 XOR gate 문제와 닮아있다. 학습 시에 MNIST의 curve한 특성이 매우 도움이 되기 때문에 Pentomino의 학습이 더 어렵다고 주장하고 있다.
사용하는 모델은 이미지의 레이블이 변경되지 않는 상태에서 이미지 내부의 랜덤하게 생성된 도형을 잘 인식할 수 있어야 한다. 하지만 회전, 크기와 같은 invariant한 속성이 많을수록 inference problem이 존재한다.
이러한 invariant한 속성을 모듈화시켜 각자 특화될 수 있도록 하는 ResMixNet을 제안한다.
모델의 첫 단은 Conv로 구성하여 low-level의 feature를 공유할 수 있도록 한다. 다음으로는 M이라고 해서 Experts를 쌓아놓은 형태의 단순한 모델이다. G(Gater)는 단순히 4개의 Conv를 쌓고, 여기서 나온 가중치와 E(Experts)에서 나온 가중치를 matrix 곱해서 최종 결과를 만들어낸다.
MNIST Parity Dataset에서는 특이하게 VGG 모델이 다른 ResNet 계열보다 성능이 좋은 것을 확인할 수 있다.
Pentomino에서는 제안한 모델이 좋은 성능을 보여주었다.
CIFAR 데이터셋에서는 차이가 거의 나지 않거나, 떨어지는 현상을 보여주었다. 논문에서 그 이유로는 CIFAR-100은 비슷한 특징을 가지는 클래스가 많기 때문이라고 하면서, 제안한 모델은 high-level의 특징을 잘 학습하지 못하는 것 같다라고 한다.(비슷한 특징을 가지는 클래스일수록, 상당히 구체적인 특징을 잘 잡아낼 수 있어야한다.)
Reference
Jo, J., Verma, V., & Bengio, Y. (2018). Modularity Matters: Learning Invariant Relational Reasoning Tasks.arXiv preprint arXiv:1806.06765.
tf.data API는 메모리에 적재하기 힘든 매우 큰 데이터셋을 다룰 때, 다양한 file format을 다룰 수 있도록 도와줍니다. 예를 들어, TFRecord file format은 많은 TF app가 학습 데이터에 사용하는 간단한 record-oriented 이진 형식입니다. tf.data.TFRecordDataset 클래스는 인풋 파이프라인에서 하나 또는 그 이상의 TFRecord 파일의 내용이 흐르도록 합니다.
French Street Name Signs (FSNS)을 사용하는 예제입니다.
# Creates a dataset that reads all of the examples from two files.
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
TFRecordDataset을 초기화하는 filenames 인자는 string, string 배열 또는 string tf.Tensor를 전달받을 수 있습니다. 만약 학습과 검증을 위해 두 개의 파일을 사용한다면, 파일 이름을 입력으로 사용하여 데이터셋을 생성하는 팩토리 메소드로 만들 수 있습니다.
많은 데이터셋은 하나 또는 그 이상의 text 파일에 분산되어 있습니다. tf.data.TextLineDataset은 준비된 텍스트 파일에서 line 단위로 추출하는 쉬운 방법을 제공합니다. 주어진 하나 또는 그 이상의 파일 이름에서, TExtLineDataset은 line 단위로 string-value를 생성해 줄 것입니다.
directory_url = 'https://storage.googleapis.com/download.tensorflow.org/data/illiad/'
file_names = ['cowper.txt', 'derby.txt', 'butler.txt']
file_paths = [
tf.keras.utils.get_file(file_name, directory_url + file_name)
for file_name in file_names
]
dataset = tf.data.TextLineDataset(file_paths)
첫 번째 파일의 5개 행을 보여줍니다.
for line in dataset.take(5):
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b'His wrath pernicious, who ten thousand woes' b"Caused to Achaia's host, sent many a soul" b'Illustrious into Ades premature,' b'And Heroes gave (so stood the will of Jove)'
Dataset.interleave는 파일을 번갈아 가면서 사용할 수 있게 해줍니다. 다음은 각 파일에서 나오는 문장의 예를 보여줍니다. cycle_length=3이므로 파일당 3개의 행씩 번갈아가면서 보여주겠군요.
files_ds = tf.data.Dataset.from_tensor_slices(file_paths)
lines_ds = files_ds.interleave(tf.data.TextLineDataset, cycle_length=3)
for i, line in enumerate(lines_ds.take(9)):
if i % 3 == 0:
print()
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b"\xef\xbb\xbfOf Peleus' son, Achilles, sing, O Muse," b'\xef\xbb\xbfSing, O goddess, the anger of Achilles son of Peleus, that brought'
b'His wrath pernicious, who ten thousand woes' b'The vengeance, deep and deadly; whence to Greece' b'countless ills upon the Achaeans. Many a brave soul did it send'
b"Caused to Achaia's host, sent many a soul" b'Unnumbered ills arose; which many a soul' b'hurrying down to Hades, and many a hero did it yield a prey to dogs and'
기본적으로 TextLineDataset은 파일의 모든 line을 살펴보기 때문에 만약 파일에 header 행이나 주석이 포함된 경우 사용이 바람직하지 않을 수 있습니다. header 행이나 주석과 같은 불필요한 내용은 Dataset.skip(), Dataset.filter()를 사용하여 배제할 수 있습니다. 다음 예제는 첫 번째 행을 건너뛰고, 생존자 데이터만 찾는 경우입니다.
만약 메모리에 데이터가 존재한다면 Dataset.from_tensor_slices를 사용하여 사전 형태로 쉽게 불러올 수 있습니다.
titanic_slices = tf.data.Dataset.from_tensor_slices(dict(df))
for feature_batch in titanic_slices.take(1):
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
take(1)을 통해 1 크기의 배치를 불러오고, dict 형태이기 때문에 items()로 value, key를 받습니다.
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
print("features:")
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
# Creates a dataset that reads all of the records from two CSV files, each with
# four float columns which may have missing values.
record_defaults = [999,999,999,999]
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults)
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
기본적으로 CsvDataset은 모든 행과 열을 반환합니다. 이는 header 행 또는 원하는 column이 포함되어 있는 경우 바람직하지 않을 수 있습니다. header와 select_cols 인자를 통해 제거할 수 있습니다.
# Creates a dataset that reads all of the records from two CSV files with
# headers, extracting float data from columns 2 and 4.
record_defaults = [999, 999] # Only provide defaults for the selected columns
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults, select_cols=[1, 3])
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
tf.data API는 복잡한 input pipeline을 재사용성, 단순하게 만들어 사용할 수 있게 합니다. 예를 들어, 이미지 모델을 위한 파이프라인은 분산 파일 시스템에서 데이터를 통합하고, 각 이미지에 랜덤 변화를 주고, 학습에서 랜덤하게 선택한 이미지를 병합하여 사용할 수 있습니다. 텍스트 모델을 위한 파이프라인은 원본 텍스트 데이터에서 심볼을 추출하고, 룩업 테이블의 임베딩 식별자로 변환하여, 길이가 다른 시퀀스를 일괄 처리할 수 있습니다. tf.data API는 대용량의 데이터를 다룰 수 있게 도와주고, 서로 다른 데이터 포맷을 읽을 수 있으며, 복잡한 변환 작업을 수행합니다.
tf.data API는 일련의 요소를 나타낼 수 있는 tf.data.Dataset abstraction을 소개합니다. 예를 들어, 이미지 파이프라인에서 요소는 이미지와 레이블을 나타내는 텐서의 요소 쌍인 단일 학습 예시를 나타낼 수 있습니다.
dataset을 생성하는 두 가지 방법이 있습니다.
data source는 메모리 또는 하나 이상의 파일에 저장된 데이터로 구성합니다.
데이터 변환은 하나 이상의 tf.data.Dataset 객체에서 데이터 세트를 구성합니다.
Basic mechanics
input pipeline을 만들기 위해서는 data source를 필수적으로 사용해야 합니다. 예를 들어, 메모리에 존재하는 데이터로 Dataset을 구성하는 경우, tf.data.Dataset.from_tensors()와 tf.data.Dataset.from_tensor_slices()를 사용합니다. 만약 TFRecord 포맷을 사용하고 있다면, tf.data.TFRecordDataset()을 사용합니다.
Dataset 객체를 가지고 있으면, tf.data.Dataset 객체의 메서드를 호출하여 새로운 Dataset을 만들 수 있습니다. 예를 들어, 원소당 변환을 수행하는 Dataset.map()이나 다중 원소 변환을 수행하는 Dataset.batch() 적용할 수 있습니다. 전체 변환 목록은 tf.data.Dataset 문서를 참조하세요.
Dataset 객체는 Python iterable합니다. for-loop를 통해 해당 요소를 사용할 수 있습니다.
여기서 tf.SparseTensor(indices=[[0, 0], [1, 2]], values =[1, 2], dense_shape=[3, 4])는 다음과 같은 결과를 보여줍니다.
[[1,0,0,0] [0,0,2,0] [0,0,0,0]]
indices는 [0, 0], [1, 2]에 각각 non-zero value가 있음을 명시합니다. 실제로 위의 결과에서 [0, 0]에는 value의 첫 번째 값인 1, [1, 2]에는 두 번째 값인 2가 출력되고 있습니다. dense_shape = [3, 4]는 (3, 4)의 2차원 텐서를 나타냅니다.
# Use value_type to see the type of value represented by the element spec
dataset4.element_spec.value_type
Humans and animals learn much better when the examples are not randomly presented but organized in a meaningful order which illustrates gradually more concepts, and gradually more complex ones. Here, we formalize such training strategies in the context of machine learning, and call them “curriculum learning”. In the context of recent research studying the difficulty of training in the presence of non-convex training criteria (for deep deterministic and stochastic neural networks), we explore curriculum learning in various set-ups. The experiments show that significant improvements in generalization can be achieved. We hypothesize that curriculum learning has both an effect on the speed of convergence of the training process to a minimum and, in the case of non-convex criteria, on the quality of the local minima obtained: curriculum learning can be seen as a particular form of continuation method (a general strategy for global optimization of non-convex functions).
인간과 동물은 무작위로 제시되지 않고, 간단한 것에서 점점 더 많은 개념과 복잡한 것을 의미있는 순서로 구성된 예제를 볼 때 더 학습을 잘한다.
우리는 머신러닝의 맥락에서 이러한 교육 전략을 공식화하고, 이를 커리큘럼 학습이라고 부른다.
non-convex 학습 기준(심층 결정론과 확률적 신경망)에서 학습의 어려움을 연구하는 최근 연구의 맥락에서, 우리는 다양한 셋업을 다루는 커리큘럼 학습을 탐구한다.
실험은 일반화에서 상당한 성능 향상을 보여주었다.
우리는 커리큘럼 학습이 학습 과정의 빠른 수렴과 non-convex의 조건하에서 local minima에 빠질 수 있는 확률이 낮아지는 효과를 가지고 있다고 가정한다.: 커리큘럼 학습은 (non-convext 함수의 전역 최적화를 위한 일반적 전략) 특정 형태의 연속 방법으로 볼 수 있다.
요약
커리큘럼 학습은 일반적으로 사람이 초급 수준의 학습부터 대학 수준의 학습내용까지 긴 기간을 가지고 학습하는 경우를 의미하는데, 이를 머신러닝의 학습에 적용해보자는 것이다.
커리큘럼 학습은 일반화와 빠른 수렴 속도의 장점을 가진다.
논문에서 언급하고 있는 continuation method는 non-convex에서 좋은 local-minima를 찾기 위한 방법이다. 이 방법은 커리큘럼 학습과 같이 먼저 초기의 objective function을 쉽게 정의하고, 차츰 objective function을 어렵게 만들어 문제를 해결하는 방법이다. 이때 local minima는 계속 유지한다.
다시, 커리큘럼 학습은 다시 쉽게 설명해서 처음에는 모델한테 쉬운 샘플만 보여주다가 점차 어려운 샘플을 보여주는 것이다. 학습 시에 전체 데이터를 한번에 학습시키는 것보다 쉬운 것과 어려운 것을 정의하여 [쉬운 것->어려운 것] 순으로 학습하라는 의미이다.
쉬운 샘플을 정의하는 방법은 두 가지를 제시하고 있다. 첫 번째는 노이즈의 개수로 판단하는 것이고, 두 번째는 가우시안 분포의 바운더리에서 margin 거리를 활용하는 방법이 있다. margin 거리가 가까울수록 쉽고, 멀수록 어려운 샘플이라고 정의한다.
실험에서는 shape recognition을 보여주고 있는데, 쉬운 샘플로는 정확한 모양의 원, 정사각형 등만 사용하고(Basic Shape), 어려운 샘플로는 직사각형, 타원 등이 포함된 것을 사용한다(Geom Shape).
Reference
Bengio, Y., Louradour, J., Collobert, R., & Weston, J. (2009, June). Curriculum learning. InProceedings of the 26th annual international conference on machine learning(pp. 41-48).
We introduce techniques for rapidly transferring the information stored in one neural net into another neural net. The main purpose is to accelerate the training of a significantly larger neural net. During real-world workflows, one often trains very many different neural networks during the experimentation and design process. This is a wasteful process in which each new model is trained from scratch. Our Net2Net technique accelerates the experimentation process by instantaneously transferring the knowledge from a previous network to each new deeper or wider network. Our techniques are based on the concept of functionpreserving transformations between neural network specifications. This differs from previous approaches to pre-training that altered the function represented by a neural net when adding layers to it. Using our knowledge transfer mechanism to add depth to Inception modules, we demonstrate a new state of the art accuracy rating on the ImageNet dataset.
이 논문은 한 가지 신경망이 담고 있는 정보를 다른 신경망으로 빠른 속도로 전이할 수 있는 방법을 소개한다.
주요 목적은 상당히 큰 신경망의 학습 속도를 가속화하는 것이다.
실제 업무에서 설계 과정과 실험동안 많은 신경망을 학습한다.
새로운 모델을 scratch에서부터 학습하는 것은 매우 소모적인 프로세스이다.
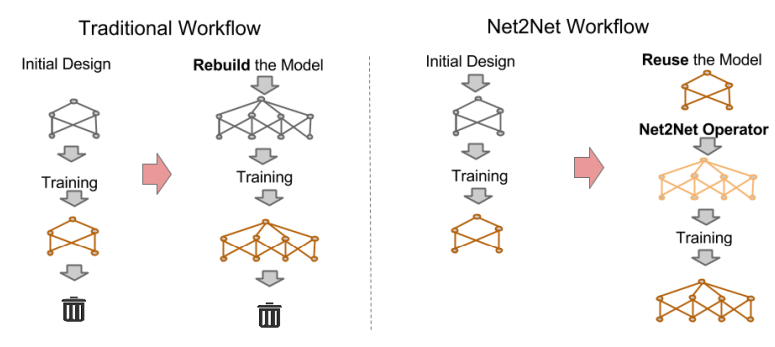
Net2Net 테크닉은 이전에 사용했던 신경망에서 더욱 깊고 와이드한 네트워크로 정보를 이전하는 실험 과정을 가속화한다.
이 기술은 신경망의 구성요소 간의 변환을 보존하는 기능을 기반으로 한다.
모델에 층을 추가할 때 신경망의 기능적 요소들이 변경되는 이전의 사전 학습과는 다른 방법이다.
이 방법을 사용하여 ImageNet 데이터셋에서 훌륭한 성능을 얻었다.
요약
이 논문은 사전 학습된 작은 크기의 신경망의 정보를 좀 더 깊고 넓은 신경망에 전이 학습하려는 방법을 제안한다.
기존의 문제를 해결할 때, 여러 가지 네트워크를 실험해보아야하고 실제로 이를 scratch부터 학습하는 것은 매우 시간이 많이 소모된다. 따라서 이 논문은 이전 네트워크의 정보를 더 큰 네트워크를 학습할 때 사용해볼 수는 없을까?에 대한 질문에서 시작된다.
기존에 존재하던 방법인 FitNets는 이와 같은 방법을 수행할 수 있지만, 트레이닝이 필요하다는 단점이 존재한다. FitNets는 이전 네트워크의 feature map을 target으로 학습하는 네트워크이다.
논문의 방법은 네트워크 구조에 제약을 주고, 트레이닝없이 transfer를 하는 것이다.
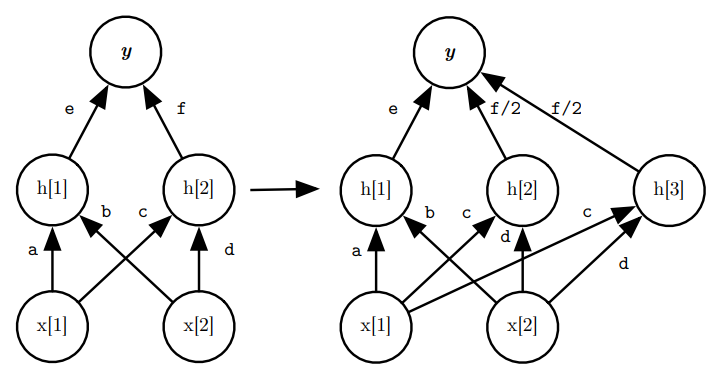
네트워크를 더욱 와이드하게 구성할 경우, Teacher Net의 노드 중 하나를 랜덤하게 골라 사용하고, 늘어난 수만큼 가중치를 1/n 해준다.
네트워크를 더욱 깊게 구성하는 경우, 간단하게 밑의 그림처럼 새 네트워크를 끼워서 Identity Mapping을 사용하는 방식이다. 대신 ReLU는 괜찮지만, sigmoid는 사용이 불가능하다.(시그모이드의 단점 때문?)
Neural networks are both computationally intensive and memory intensive, making them difficult to deploy on embedded systems with limited hardware resources. To address this limitation, we introduce “deep compression”, a three stage pipeline: pruning, trained quantization and Huffman coding, that work together to reduce the storage requirement of neural networks by 35× to 49× without affecting their accuracy. Our method first prunes the network by learning only the important connections. Next, we quantize the weights to enforce weight sharing, finally, we apply Huffman coding. After the first two steps we retrain the network to fine tune the remaining connections and the quantized centroids. Pruning, reduces the number of connections by 9× to 13×; Quantization then reduces the number of bits that represent each connection from 32 to 5. On the ImageNet dataset, our method reduced the storage required by AlexNet by 35×, from 240MB to 6.9MB, without loss of accuracy. Our method reduced the size of VGG-16 by 49× from 552MB to 11.3MB, again with no loss of accuracy. This allows fitting the model into on-chip SRAM cache rather than off-chip DRAM memory. Our compression method also facilitates the use of complex neural networks in mobile applications where application size and download bandwidth are constrained. Benchmarked on CPU, GPU and mobile GPU, compressed network has 3× to 4× layerwise speedup and 3× to 7× better energy efficiency.
신경망은 계산 및 메모리 집약적인 특성 떄문에 하드웨어 자원이 제한되어 있는 임베딩 환경에서 작동시키기가 어렵다.
이러한 제한점을 해결하기 위해, 정확도 손실 없이 35배에서 49배 저장 요구를 감소하는 작업을 수행하는 허프만 코딩, 프루닝, 학습 양자화의 세 가지 단계를 가지는 "deep compression"을 소개한다.
이 방법은 먼저 중요한 연결만 학습하도록 네트워크를 프루닝합니다.
다음으로 가중치 공유를 위해 가중치를 양자화하고, 마지막으로 허프만 코딩을 적용한다.
위의 두 가지 단계 이후에 나머지 연결과 양자화된 것들의 미세 조정을 위해 네트워크를 재학습합니다.
프루닝은 연결의 수를 9배에서 13배 감소시키고, 양자화는 각 연결을 나타내는 비트 수를 32에서 5로 줄입니다.
이미지넷 데이터셋에서 이 방법은 정확도 손실 없이 알렉스넷의 저장요구를 35배 줄였다.(240MB -> 6.9MB)
또한, 정확도 손실 없이 VGG-16 모델의 크기를 49배 감소시켰다.(552MB -> 11.3MB)
이는 off-chip DRAM memory이 아닌 on-chip SRAM에서의 모델 피팅을 가능케 한다.
우리의 압축 방법은 애플리케이션 크기와 다운로드 대역폭이 제한된 모바일 앱에서 복잡한 신경망 사용을 가능하게 한다.
CPU, GPU, 모바일 GPU에서 압축된 네트워크는 3 ~ 4배 빠른 속도와 3 ~ 7배 향상된 에너지 효율성을 나타낸다.
요약
논문에서 제안하는 방법의 과정은 Pruning -> Quantization -> huffman coding이다.
허프만 코딩은 확률에 따라 비트의 수가 달라진다는 점과 효과적인 디코딩 방법을 적용한다는 것이다.
프루닝은 의미없는 네트워크 간 연결을 전부 끊어버리는 것을 의미한다. 이 같은 방법을 반복하면서 정확도를 유지하도록 한다.
Quantization은 일정 값으로 나누거나 대표값을 저장하는 것을 의미한다. 여기서는 대표값의 인덱스를 저장하여 비트수를 감소시킨다. 이러한 대표값은 quantization 과정의 동일 인덱스는 전부 동일 대표값을 사용하게 된다. 예를 들어, 밑의 그림에서 index 1은 전부 파란색 값을 사용하는 것과 같은 경우이다.
Quantization의 초기화는 uniform init이 가장 좋은 결과를 보여주는데, 그 이유는 다른 초기화 같은 경우는 크거나 작은 가중치를 고려하지 않는 결과가 발생하기 때문에 이 부분에서 정확도 감소가 일어난다고 한다.
프루닝 또는 quantization만 사용한 경우보다 동시에 사용한 경우의 weight distribution이 좋게 나타나서 정확도 손실이나 모델 압축 측면에서 효과적이다.
Reference
Han, S., Mao, H., & Dally, W. J. (2015). Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding.arXiv preprint arXiv:1510.00149.