Keras model을 변경하고 읽거나 학습, 평가, 추론하는 동안에 custom callbacks는 Keras model을 customize하는데에 있어서 강력한 도구입니다. 그 예로 tf.keras.callbacks가 있습니다. 또한, Tensorboard는 학습 진전과 결과를 도출하고 시각화할 수 있으며, tf.keras.callbacks.ModelCheckpoint는 자동적으로 학습 또는 그 외의 행동에 대한 결과를 자동으로 저장해줍니다. 이
이번 가이드에서는 이러한 것들이 무엇을 하며 언제 불리는지에 대해 다루고 어떻게 build하는지 설명합니다.
Introduction to Keras callbacks
케라스에서 Callback은 학습(batch/epoch start and ends), 평가, 추론의 다양한 단계에서 호출할 수 있는 메소드의 집합으로서 기능적으로 구체적인 정보들에 대해 접근할 수 있습니다. 학습하는 동안 모델의 statistics(accuracy, recall etc.)와 내부 상태를 관찰하는데 매우 유용합니다.
tf.keras.Model.fit(), tf.keras.Model.evaluate(), tf.keras.Model.predict()에 callbacks list인자를 주어 사용할 수 있습니다.
먼저 tensorflow를 import하고 간단한 모델을 만들어 봅니다.
# Define the Keras model to add callbacks to
def get_model():
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(1, activation = 'linear', input_dim = 784))
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=0.1), loss='mean_squared_error', metrics=['mae'])
return model
# Load example MNIST data and pre-process it
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = x_train.reshape(60000, 784).astype('float32') / 255
x_test = x_test.reshape(10000, 784).astype('float32') / 255
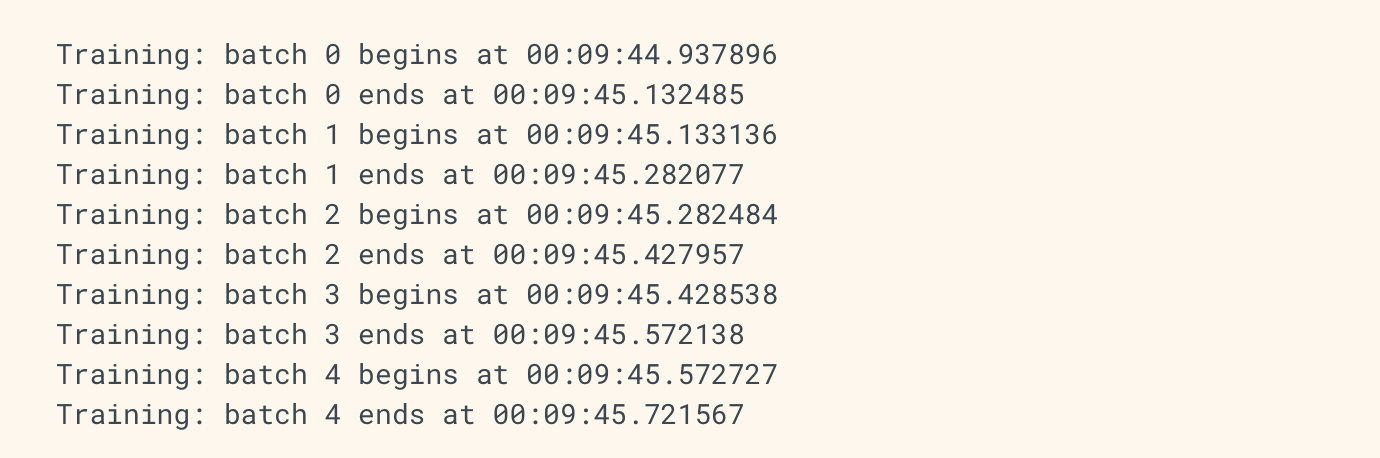
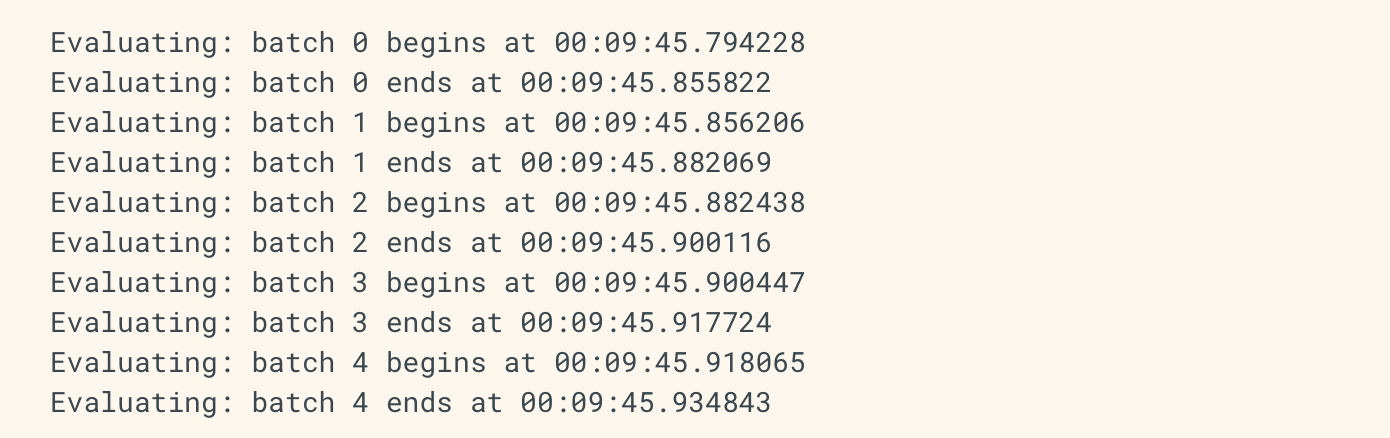
이제 batch start, end를 추적할 수 있는 간단한 custom callback을 작성합니다. 이 코드는 각 batch에 대한 정보를 나타냅니다.
import datetime
class MyCustomCallback(tf.keras.callbacks.Callback):
def on_train_batch_begin(self, batch, logs=None):
print('Training: batch {} begins at {}'.format(batch, datetime.datetime.now().time()))
def on_train_batch_end(self, batch, logs=None):
print('Training: batch {} ends at {}'.format(batch, datetime.datetime.now().time()))
def on_test_batch_begin(self, batch, logs=None):
print('Evaluating: batch {} begins at {}'.format(batch, datetime.datetime.now().time()))
def on_test_batch_end(self, batch, logs=None):
print('Evaluating: batch {} ends at {}'.format(batch, datetime.datetime.now().time()))
tf.keras.Model.fit()의 인자로 전달해주면 각 단계에 대한 정보를 제공합니다.
logs dict는 loss value, epoch or batch의 metrics를 포함합니다.
class LossAndErrorPrintingCallback(tf.keras.callbacks.Callback):
def on_train_batch_end(self, batch, logs=None):
print('For batch {}, loss is {:7.2f}.'.format(batch, logs['loss']))
def on_test_batch_end(self, batch, logs=None):
print('For batch {}, loss is {:7.2f}.'.format(batch, logs['loss']))
def on_epoch_end(self, epoch, logs=None):
print('The average loss for epoch {} is {:7.2f} and mean absolute error is {:7.2f}.'.format(epoch, logs['loss'], logs['mae']))
model = get_model()
_ = model.fit(x_train, y_train,
batch_size=64,
steps_per_epoch=5,
epochs=3,
verbose=0,
callbacks=[LossAndErrorPrintingCallback()])
이와 같이, evaluate()에서도 동일하게 사용가능합니다.
Examples of Keras callback applications
Early stopping at minimum loss
다음 예제는 model.stop_training(boolean)을 이용하여 최소 loss에 도달했을때 학습을 중단시킵니다.
학습을 중단하기 전에 사용자가 얼마나 기다려야 하는지에 대한 정보를 patience로 제공받게 됩니다.
(patience가 10이라면 최소 손실로부터 10epoch동안 변화가 없을 시 earlystop)
import numpy as np
class EarlyStoppingAtMinLoss(tf.keras.callbacks.Callback):
"""Stop training when the loss is at its min, i.e. the loss stops decreasing.
Arguments:
patience: Number of epochs to wait after min has been hit. After this
number of no improvement, training stops.
"""
def __init__(self, patience=0):
super(EarlyStoppingAtMinLoss, self).__init__()
self.patience = patience
# best_weights to store the weights at which the minimum loss occurs.
self.best_weights = None
def on_train_begin(self, logs=None):
# The number of epoch it has waited when loss is no longer minimum.
self.wait = 0
# The epoch the training stops at.
self.stopped_epoch = 0
# Initialize the best as infinity.
self.best = np.Inf
def on_epoch_end(self, epoch, logs=None):
current = logs.get('loss')
if np.less(current, self.best):
self.best = current
self.wait = 0
# Record the best weights if current results is better (less).
self.best_weights = self.model.get_weights()
else:
self.wait += 1
if self.wait >= self.patience:
self.stopped_epoch = epoch
self.model.stop_training = True
print('Restoring model weights from the end of the best epoch.')
self.model.set_weights(self.best_weights)
def on_train_end(self, logs=None):
if self.stopped_epoch > 0:
print('Epoch %05d: early stopping' % (self.stopped_epoch + 1))
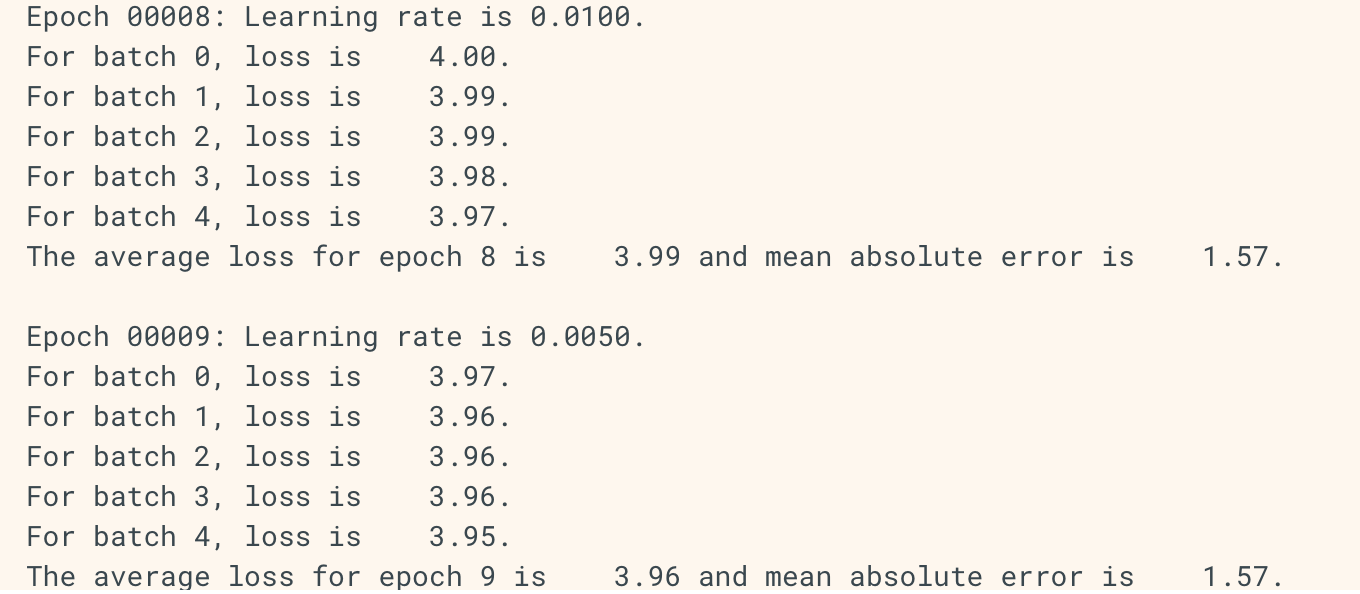
모델 학습동안에 일반적으로 행하는 것은 epochs에 따라 learning rate를 decay시켜주는 것입니다. Keras backend는 get_value api를 통해 이를 접근합니다. 이 예제에서 learning rate가 custom Callback에 의해 어떻게 동적으로 변화하는지 보겠습니다.
tf.keras.callbacks.LearningRateScheduler는 보다 일반적인 구현을 제공합니다.
class LearningRateScheduler(tf.keras.callbacks.Callback):
"""Learning rate scheduler which sets the learning rate according to schedule.
Arguments:
schedule: a function that takes an epoch index
(integer, indexed from 0) and current learning rate
as inputs and returns a new learning rate as output (float).
"""
def __init__(self, schedule):
super(LearningRateScheduler, self).__init__()
self.schedule = schedule
def on_epoch_begin(self, epoch, logs=None):
if not hasattr(self.model.optimizer, 'lr'):
raise ValueError('Optimizer must have a "lr" attribute.')
# Get the current learning rate from model's optimizer.
lr = float(tf.keras.backend.get_value(self.model.optimizer.lr))
# Call schedule function to get the scheduled learning rate.
scheduled_lr = self.schedule(epoch, lr)
# Set the value back to the optimizer before this epoch starts
tf.keras.backend.set_value(self.model.optimizer.lr, scheduled_lr)
print('\nEpoch %05d: Learning rate is %6.4f.' % (epoch, scheduled_lr))
keras.backend.get_value와 set_value에 주목 + self.model.optimizer.lr이 현재 모델의 learning rate에 대한 정보를 제공합니다.
tf.keras.callbacks.Callback은 기본적으로 model에 대한 정보를 가지고 있습니다. self.으로 접근.
LR_SCHEDULE = [
# (epoch to start, learning rate) tuples
(3, 0.05), (6, 0.01), (9, 0.005), (12, 0.001)
]
def lr_schedule(epoch, lr):
"""Helper function to retrieve the scheduled learning rate based on epoch."""
if epoch < LR_SCHEDULE[0][0] or epoch > LR_SCHEDULE[-1][0]:
return lr
for i in range(len(LR_SCHEDULE)):
if epoch == LR_SCHEDULE[i][0]:
return LR_SCHEDULE[i][1]
return lr
model = get_model()
_ = model.fit(x_train, y_train,
batch_size=64,
steps_per_epoch=5,
epochs=15,
verbose=0,
callbacks=[LossAndErrorPrintingCallback(), LearningRateScheduler(lr_schedule)])
NMS라고 불리우는 함수이며, 모델이 예측한 bbox중 겹치는 부분이 많은 것들을 제거한다.
다음과 같은 과정을 거친다
1. 가장 높은 Score를 가진 순대로 내림차순한다.
2. 선택된 bbox와 나머지 bbox의 IOU를 계산한다. 이때, IOU threshold(보통 0.5)이상이면 제거해준다.
3. 객체당 하나의 bbox가 남거나 더 이상 계산할 bbox가 없을 때까지 위의 과정을 반복하게 된다.
아래가 non_max_suppression의 구현이다.
import numpy as np
def non_max_suppression(boxes, overlapThresh):
if(len(boxes) == 0):
raise ValueError('nonono')
picked_class = []
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
area = (x2 - x1 + 1) * (y2 - y1 + 1)
idxs = np.argsort(y2)
print(idxs)
pick = []
while len(idxs) > 0:
# grab the last index in the indexes list and add the
# index value to the list of picked indexes
last = len(idxs) - 1
i = idxs[last]
print(last, i)
pick.append(i)
# find the largest (x, y) coordinates for the start of
# the bounding box and the smallest (x, y) coordinates
# for the end of the bounding box
xx1 = np.maximum(x1[i], x1[idxs[:last]])
yy1 = np.maximum(y1[i], y1[idxs[:last]])
xx2 = np.minimum(x2[i], x2[idxs[:last]])
yy2 = np.minimum(y2[i], y2[idxs[:last]])
# compute the width and height of the bounding box
w = np.maximum(0, xx2 - xx1 + 1)
h = np.maximum(0, yy2 - yy1 + 1)
# compute the ratio of overlap
overlap = (w * h) / area[idxs[:last]]
print('overlap : ',overlap)
# delete all indexes from the index list that have
idxs = np.delete(idxs, np.concatenate(([last],
np.where(overlap > overlapThresh)[0])))
print('idx : ', idxs)
# return only the bounding boxes that were picked using the
# integer data type
return boxes[pick].astype("int")
# Save predictions for future checks
predictions = model.predict(x_test)
Whole-model saving
빌드된 모델을 하나로 저장할 수 있습니다. 모델을 만든 코드가 더 이상 남아있지 않더라도 이 파일을 통해 다시 사용할 수 있습니다.
파일에는 다음 내용이 포함됩니다.
모델 구조
weight values
training config(compile)
optimizer and state
# Save the model
model.save('path_to_my_model.h5')
# Recreate the exact same model purely from the file
new_model = keras.models.load_model('path_to_my_model.h5')
import numpy as np
# Check that the state is preserved
new_predictions = new_model.predict(x_test)
np.testing.assert_allclose(predictions, new_predictions, atol=1e-6)
# Note that the optimizer state is preserved as well:
# you can resume training where you left off.
Export to SavedModel
전체모델을 Tensorflow savedmodel format으로 추출할 수 있습니다. Tensorflow 객체용 독립형 serialization format이며 Python 이외의 Tensorflow 구현 뿐만아니라 Tensorflow Serving기능도 제공합니다.
# Export the model to a SavedModel
keras.experimental.export_saved_model(model, 'path_to_saved_model')
# Recreate the exact same model
new_model = keras.experimental.load_from_saved_model('path_to_saved_model')
# Check that the state is preserved
new_predictions = new_model.predict(x_test)
np.testing.assert_allclose(predictions, new_predictions, atol=1e-6)
# Note that the optimizer state is preserved as well:
# you can resume training where you left off.
SavedModel은 다음을 포함합니다.
model weights를 포함한 Tensorflow checkpoint
Tensorflow graph가 포함된 SavedModel 프로토타입. 예측(Serving), 학습, 평가를 위한 별도의 그래프. 이전에 compile하지 않았다면, inference 그래프만 추출됨.
모델 구조
Architecture-only saving
weight나 optimizer는 관심이 없고, 오로지 모델 구조에만 관심이 가는 경우가 있습니다. 이러한 경우에 get_config()를 통해 모델의 config를 검색하면 됩니다. 같은 모델을 재생성할 수 있도록 파이썬 dict구조로 되어 있습니다. 이렇게 불러진 모델은 이전에 학습한 정보는 가지고 있지 않습니다.
config = model.get_config()
reinitialized_model = keras.Model.from_config(config)
# Note that the model state is not preserved! We only saved the architecture.
new_predictions = reinitialized_model.predict(x_test)
assert abs(np.sum(predictions - new_predictions)) > 0.
python dict대신에 to_json(), from_json()을 사용하여 JSON으로도 저장할 수 있습니다. disk에 저장할 때 유용하게 사용됩니다.
weights에만 관심이 있는 경우에 get_weights()를 사용하여 Numpy array로 이루어진 weights를 찾을 수 있습니다. 또한, 모델의 상태를 set_weights로 변경할 수 있습니다.
weights = model.get_weights() # Retrieves the state of the model.
model.set_weights(weights) # Sets the state of the model.
get_config() / from_config() 와 get_weights() / set_weights()를 적절히 섞어 사용할 수 있습니다. 하지만, model.save()와는 다르게 이들은 학습 config와 optimizer를 포함하지 않습니다. 따라서 compile을 다시 설정해주어야 합니다.
config = model.get_config()
weights = model.get_weights()
new_model = keras.Model.from_config(config)
new_model.set_weights(weights)
# Check that the state is preserved
new_predictions = new_model.predict(x_test)
np.testing.assert_allclose(predictions, new_predictions, atol=1e-6)
# Note that the optimizer was not preserved,
# so the model should be compiled anew before training
# (and the optimizer will start from a blank state).
get_weights() / set_weights()와 같은 의미이면서 디스크에 저장하려면 save_weighs(fpath) / load_weights(fpath)를 사용하면 됩니다.
# Save JSON config to disk
json_config = model.to_json()
with open('model_config.json', 'w') as json_file:
json_file.write(json_config)
# Save weights to disk
model.save_weights('path_to_my_weights.h5')
# Reload the model from the 2 files we saved
with open('model_config.json') as json_file:
json_config = json_file.read()
new_model = keras.models.model_from_json(json_config)
new_model.load_weights('path_to_my_weights.h5')
# Check that the state is preserved
new_predictions = new_model.predict(x_test)
np.testing.assert_allclose(predictions, new_predictions, atol=1e-6)
# Note that the optimizer was not preserved.
이는 너무 복잡하니 다음과 같은 방법을 추천드립니다.
model.save('path_to_my_model.h5')
del model
model = keras.models.load_model('path_to_my_model.h5')
Weights-only saving in SavedModel format
save_weights는 keras에서 HDF5 format, Tensorflow에서 SavedModel format 형태를 만들어 냅니다. 이러한 형식은 사용자가 제공하는 되로 선택되어집니다. ".h5", "keras"인 경우는 Keras HDF5 형식을 사용합니다. 다른 모든 항목은 SavedModel로 기본 설정 됩니다.
model.save_weights('path_to_my_tf_savedmodel')
명시적으로 save_format인자("tf" or "h5")를 전달하여 설정할 수 있습니다.
Sequential, Functional Model은 DAG of layers를 나타내는 데이터구조입니다. 이들은 안전하게 serialized, deserialized될 수 있습니다.
subclassed되어진 모델은 데이터 구조가 아닌 그저 코드의 일부분일 뿐입니다. 이러한 모델의 구조는 call method에서 정의됩니다. 이는 모델이 안전하게 serialized될 수 없다는 것을 의미합니다.
모델을 불러오기 위해, 모델을 생성한 코드(the code of the model subclass)에 접근할 수 있어야합니다. 대신, 이러한 코드를 바이트코드(pickling)로 serializing할 수 있지만 안전하지 않습니다.
class ThreeLayerMLP(keras.Model):
def __init__(self, name=None):
super(ThreeLayerMLP, self).__init__(name=name)
self.dense_1 = layers.Dense(64, activation='relu', name='dense_1')
self.dense_2 = layers.Dense(64, activation='relu', name='dense_2')
self.pred_layer = layers.Dense(10, activation='softmax', name='predictions')
def call(self, inputs):
x = self.dense_1(inputs)
x = self.dense_2(x)
return self.pred_layer(x)
def get_model():
return ThreeLayerMLP(name='3_layer_mlp')
model = get_model()
우선, 한번도 사용되지 않은 모델은 저장할 수 없습니다.
subclassed model은 weights를 생성하기 위해 한번쯤은 데이터가 필요하기 때문입니다.
모델이 호출될 때 까지, input dtype, shape를 알 수 없고 weight variable또한 마찬가지입니다. Functional Model은 가장 처음에 keras.Input을 통해 input dtype, shape를 정의하기 때문에 이러한 문제가 없습니다.
subclassed model을 저장하는데에 추천하는 방법은 model과 연관된 모든 variable을 담고있는 Tensorflow SavedModel checkpoint를 만드는 save_weights()를 사용하는 것입니다.(weights, optimizer state, etc.)
model.save_weights('path_to_my_weights', save_format='tf')
# Save predictions for future checks
predictions = model.predict(x_test)
# Also save the loss on the first batch
# to later assert that the optimizer state was preserved
first_batch_loss = model.train_on_batch(x_train[:64], y_train[:64])
모델을 복원하기 위해선 만들어진 모델 객체에 접근할 수 있어야합니다.
metric, optimizer의 상태를 복원하려면 model을 compile하고 load_weights를 호출하기 전에 일부 데이터를 호출해야합니다.
# Recreate the model
new_model = get_model()
new_model.compile(loss='sparse_categorical_crossentropy',
optimizer=keras.optimizers.RMSprop())
# This initializes the variables used by the optimizers,
# as well as any stateful metric variables
new_model.train_on_batch(x_train[:1], y_train[:1])
# Load the state of the old model
new_model.load_weights('path_to_my_weights')
# Check that the model state has been preserved
new_predictions = new_model.predict(x_test)
np.testing.assert_allclose(predictions, new_predictions, atol=1e-6)
# The optimizer state is preserved as well,
# so you can resume training where you left off
new_first_batch_loss = new_model.train_on_batch(x_train[:64], y_train[:64])
assert first_batch_loss == new_first_batch_loss