다양한 문제를 해결하고, 만들어내고 있는 GPT-3가 연일 화제가 되면서 인공지능 관련 모든 분야에서 굉장히 뜨거운 반응을 보이고 있습니다. NLP뿐만 아니라 Computer Vision task도 해결할 수 있음을 보였는데, 이러한 결과가 매우 매력적일 수밖에 없습니다. 물론 사용된 파라미터 수, 학습 시간 등을 고려해보면 개인적으로 어떻게 활용할 수 있을까에 대한 좌절감도 동시에 다가옵니다.
트렌드를 빠른 속도로 파악하고 제시하고 있는 Andrew Ng님도 Transformer, BERT, GPT-3가 매우 대단한 결과를 보이고 있음을 이야기하고, NLP 분야의 수요가 지속적으로 늘어날 것을 이야기할 정도입니다.
BERT에 관심이 있는, NLP에 관심이 있다면 반드시 밑의 세 가지 논문을 요약으로라도 읽어봐야 합니다.
- papers.nips.cc/paper/7181-attention-is-all-you-need.pdf (Attention, Transformer 관련)
- arxiv.org/pdf/1810.04805.pdf (BERT 논문)
- arxiv.org/pdf/2005.14165.pdf (GPT-3 논문, 매우 길어서 요약된 내용을 보는 것을 추천합니다)
이 중에서도 이번 글에서는 BERT를 직접 공부하면서 도움이 될만한 몇 가지 사항을 정리하였습니다. 이전에 연관 논문을 읽고 BERT라는 주제를 공부하면 매우 도움이 되겠지만, 순서가 뒤바뀌어도 문제 될게 없습니다.
BERT
Transformer architecture을 중점적으로 사용한 BERT는 Bidirectional Encoder Representations from Transformers을 의미합니다. 바로 BERT에서 살펴볼 주요한 사항을 살펴보겠습니다.
들어가기 전에, BERT는 text classification, answering 등을 해결할 수 있는 모델이지만, 이보다는 Language Representation을 해결하기 위해 고안된 구조라는 것을 알아주세요.
(즉, 단어, 문장, 언어를 어떻게 표현할까에 관한 고민이고, 이를 잘 표현할 수 있다면 다양한 task를 해결할 수 있습니다.)
BERT는 양방향성을 포함하여 문맥을 더욱 자연스럽게 파악할 수 있습니다.
Bidirectional은 직역하는 것과 동일하게 BERT 모델이 양방향성 특성을 가지고 이를 적용할 수 있다는 것을 의미합니다.
이를 사용하기 이전의 대부분 모델은 문장이 존재하면 왼쪽에서 오른쪽으로 진행하여 문맥(context)를 파악하는 방법을 지녔는데요. 이는 전체 문장을 파악하는 데 있어서 당연히 제한될 수 밖에 없는 한계점입니다.
쉽게 생각해보면, '나는 하늘이 예쁘다고 생각한다'라는 문장을 이해할 때, 단순히 '하늘'이라는 명사를 정해놓고 '예쁘다'라는 표현을 사용하지는 않습니다. '예쁘다'를 표현하고 싶어서 '하늘'이라는 명사를 선택했을 수도 있습니다. 즉, 앞에서 뒤를 볼수도 있지만, 뒤에서 앞을 보는 경우도 충분히 이해할 수 있어야 전체 맥락을 완전히 파악할 수 있다는 것이죠.

이 예가 아니더라도 동의어를 파악하기 위해선 앞뒤 단어의 관계성을 파악해야 한다는 점을 이해할 수 있습니다.
-> 긍정적인 의미의 잘했다와 부정적인 의미의 잘했다.
ex1) A: "나 오늘 주식 올랐어!", B: "진짜 잘했다"
ex2) A: "나 오늘 주식으로 망했어", B: "진짜 잘~했다"
결론적으로는 기존 단방향성 모델은 성능 향상, 문맥 파악에 한계점이 존재했었고, 이를 해결하기 위해 양방향성을 띄는 모델을 제안하는 방향으로 진행된 것입니다. (RNN과 Bidirectional RNN의 차이점을 살펴도 같은 문제를 해결하기 위한 것을 알 수 있습니다)
BERT는 pre-training이 가능한 모델입니다.
이전에 존재하던 NLP 모델은 pre-training이 어려웠기 때문에 특정 task가 존재할 경우 처음부터 학습시켜야 하는 단점이 존재했습니다. 각종 Image task를 해결하는 데 있어서도 pre-trianing이 매우 큰 역할을 하고 있다는 점을 보면, NLP에서도 여러 task에 transfer하기 위해서는 이를 활용할 수 있는 모델이 매우 시급했습니다.
이에 대한 연구가 매우 활발히 진행되었고, 대표적으로 ELMO, XLNet, BERT, GPT 등 모델이 만들어지게 되었죠.
엄청난 수의 Wikipedia와 BooksCorpus 단어를 학습한 BERT를 다양한 task에 적용하고, fine-tuning해서 사용할 수 있는 것은 매우 큰 장점으로 우리에게 다가올 수 밖에 없습니다.
BERT는 주로 어떤 문제에 적용할 수 있을까요?
대표적으로 해결할 수 있는 몇 가지 문제를 알려드리겠습니다. 하지만 여기서 설명되지 않은 다양한 분야가 매우 다양하게 존재하다는 것을 잊어버리면 안됩니다. 아래 문제들은 대부분 NLP task에서 볼 수 있는 대표적인 문제들입니다.
- Question and Answering
- 주어진 질문에 적합하게 대답해야하는 매우 대표적인 문제입니다.
- KoSQuAD, Visual QA etc. - Machine Translation
- 구글 번역기, 네이버 파파고입니다. - 문장 주제 찾기 또는 분류하기
- 역시나 기존 NLP에서도 해결할 수 있는 문제는 당연히 해결할 수 있습니다. - 사람처럼 대화하기
- 이와 같은 주제에선 매우 강력함을 보여줍니다. - 이외에도 직접 정의한 다양한 문제에도 적용 가능합니다. 물론 꼭 NLP task일 필요는 없습니다.
어떻게 학습되었는지 알아보자
기본적으로 BERT는 'Attention is all you need" 논문에서 볼 수 있는 Transformer 구조를 중점적으로 사용한 구조입니다. 특히
self-attiotion layer를 여러 개 사용하여 문장에 포함되어 있는 token 사이의 의미 관계를 잘 추출할 수 있습니다.
BERT는 transformer 구조를 사용하면서도 encoder 부분만 사용(아래 그림에서 왼쪽 부분)하여 학습을 진행했는데요. 기존 모델은 대부분 encoder-decoder으로 이루어져 있으며, GPT 또한, decoder 부분을 사용하여 text generation 문제를 해결하는 모델입니다. Transformer 구조 역시, input에서 text의 표현을 학습하고, decoder에서 우리가 원하는 task의 결과물을 만드는 방식으로 학습이 진행됩니다.

BERT는 decoder를 사용하지 않고, 두 가지 대표적인 학습 방법으로 encoder를 학습시킨 후에 특정 task의 fine-tuning을 활용하여 결과물을 얻는 방법으로 사용됩니다.
어떻게 학습되었는지 알아보자 - input Representation
역시나 어떤 주제이던 데이터 처리에 관한 이야기는 빠질 수가 없습니다. BERT는 학습을 위해 기존 transformer의 input 구조를 사용하면서도 추가로 변형하여 사용합니다. Tokenization은 WorldPiece 방법을 사용하고 있습니다.
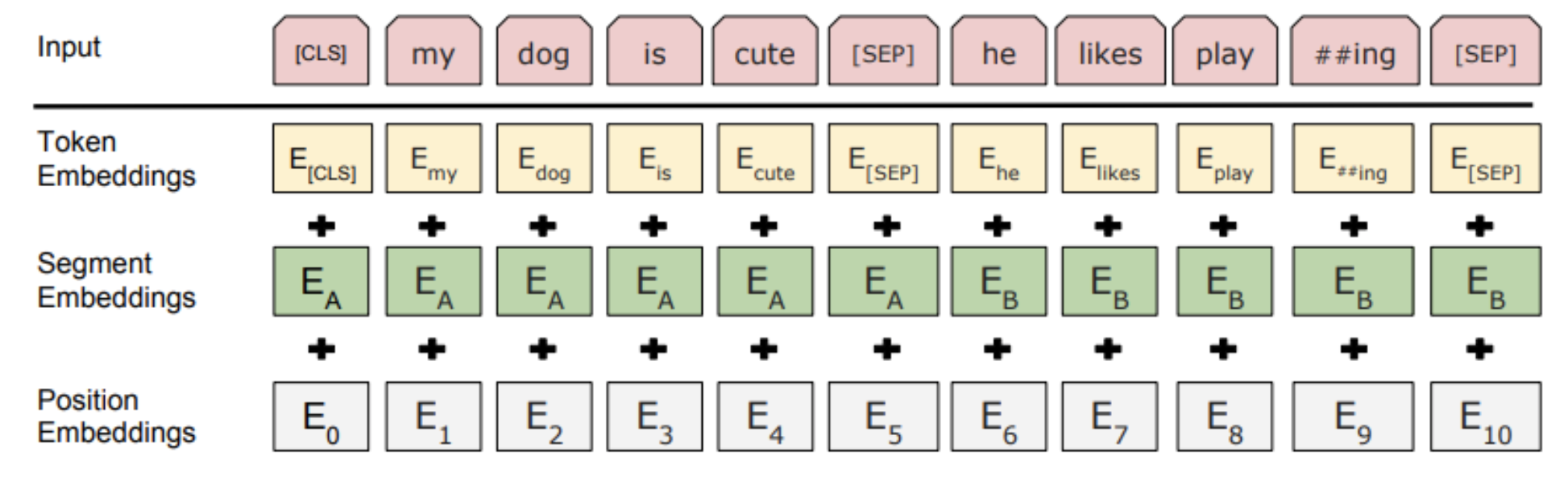
위 그림처럼 세 가지 임베딩(Token, Segment, Position)을 사용해서 문장을 표현합니다.
먼저 Token Embedding에서는 두 가지 특수 토큰(CLS, SEP)을 사용하여 문장을 구별하게 되는데요. Special Classification token(CLS)은 모든 문장의 가장 첫 번째(문장의 시작) 토큰으로 삽입됩니다. 이 토큰은 Classification task에서는 사용되지만, 그렇지 않을 경우엔 무시됩니다.
또, Special Separator token(SEP)을 사용하여 첫 번째 문장과 두 번째 문장을 구별합니다. 여기에 segment Embedding을 더해서 앞뒤 문장을 더욱 쉽게 구별할 수 있도록 도와줍니다. 이 토큰은 각 문장의 끝에 삽입됩니다.
Position Embedding은 transformer 구조에서도 사용된 방법으로 그림고 같이 각 토큰의 위치를 알려주는 임베딩입니다.
최종적으로 세 가지 임베딩을 더한 임베딩을 input으로 사용하게 됩니다.
어떻게 학습되었는지 알아보자 - Pre-training
BERT는 문장 표현을 학습하기 위해 두 가지 unsupervised 방법을 사용합니다.
- Masked Language Model
- Next Sentence Model
Masked Language Model (MLM)
문장에서 단어 중의 일부를 [Mask] 토큰으로 바꾼 뒤, 가려진 단어를 예측하도록 학습합니다. 이 과정에서 BERT는 문맥을 파악하는 능력을 기르게 됩니다.
ex) 나는 하늘이 예쁘다고 생각한다 -> 나는 하늘이 [Mask] 생각한다.
ex) 나는 하늘이 예쁘다고 생각한다 -> 나는 하늘이 흐리다고 생각한다.
ex) 나는 하늘이 예쁘다고 생각한다 -> 나는 하늘이 예쁘다고 생각한다.
추가적으로 더욱 다양한 표현을 학습할 수 있도록 80%는 [Mask] 토큰으로 바꾸어 학습하지만, 나머지 10%는 token을 random word로 바꾸고, 마지막 10%는 원본 word 그대로를 사용하게 됩니다.
Next Sentence Prediction (NSP)
다음 문장이 올바른 문장인지 맞추는 문제입니다. 이 문제를 통해 두 문장 사이의 관계를 학습하게 됩니다.
문장 A와 B를 이어 붙이는데, B는 50% 확률로 관련 있는 문장(IsNext label) 또는 관련 없는 문장(NotNext label)을 사용합니다.
QA(Question Answering)나 NLI(Natural Language Inference) task의 성능 향상에 영향을 끼친다고 합니다.
이런 방식으로 학습된 BERT를 fine-tuning할 때는 (Classification task라면)Image task에서의 fine-tuning과 비슷하게 class label 개수만큼의 output을 가지는 Dense Layer를 붙여서 사용합니다.
Reference
- www.kaggle.com/abhinand05/bert-for-humans-tutorial-baseline
- towardsdatascience.com/bert-explained-state-of-the-art-language-model-for-nlp-f8b21a9b6270
- mino-park7.github.io/nlp/2018/12/12/bert-논문정리/?fbclid=IwAR3S-8iLWEVG6FGUVxoYdwQyA-zG0GpOUzVEsFBd0ARFg4eFXqCyGLznu7w
- stackoverflow.com/questions/62705268/why-bert-transformer-uses-cls-token-for-classification-instead-of-average-over
'# Machine Learning > 글 공부' 카테고리의 다른 글
| 이제 금융권에서는 딥러닝으로 고객을 분석합니다? (0) | 2020.11.23 |
|---|---|
| 추천 시스템(Recommendation System) 공부 정리 (1) (0) | 2020.09.16 |
| 클래스 불균형, UnderSampling & OverSampling (0) | 2019.09.06 |
| keras, Model RAM 놓지 않는 현상 (2) | 2019.08.20 |
| Tensorflow 특정 gpu 사용하기 (0) | 2019.07.22 |