립시츠 함수를 다루는 이유는 아래 BatchNormalization 내용을 다룬 논문 때문입니다.
How Does Batch Normalization Help Optimization?
기존 BN 논문에서는 'BN은 Internal Covariance(내부 공변량 변화, 가끔 가다보면 내부 공선성이라고 표현하기도 하더라, 여기서는 더 많이 사용되는 내부 공변량 변화를 사용하겠습니다)을 해결하기 때문에 잘된다.'라고 주장합니다. 위 논문은 이에 반례를 제공하고, 한 단계 나아가 BN이 왜 잘되는지 수학적으로 증명하고 있으니 이를 조금씩 살펴보겠습니다.
(논문 소개와 립시츠 함수에 관한 글)

Internal Covariance
먼저 내부 공변량 변화를 쉽게 설명하자면, 우리가 흔히 사용하는 hidden layer는 당연하게도 input을 받아들이고 output을 내보냅니다. 또, 이렇게 도출된 output은 다음 단계에서 hidden layer의 input으로 활용되죠. 문제는 여기에 있습니다. 이전 층의 불규칙한 output으로 인해 다음 층의 input distribution이 급격히 변화하고, 이러한 문제가 최종적으로 학습에 큰 영향을 끼치게되어 좋지 않은 성능을 가져다 주는 문제입니다.
즉, 사공이 많으면 배가 산으로 가듯이 기존 입력값의 분포가 여러 가지 모양을 가지게 되니 해결하고자 하는 데이터의 분포를 학습할 수도 없고, 모델 입장에서는 혼란을 가지게 되어 우리에게 안좋은 성능을 가져다줍니다. 하지만 BN은 충분히 다양한 모델 구조에서도 자신의 성능을 증명했듯이, 이러한 문제를 해결할 수 있다고 합니다. BN은 다양한 장점을 가지고 있지만 그 중, 규제화(Regularizer) 기능을 이용하면, 이러한 문제가 해결되어 좋은 성능을 가지게 해준다고 합니다. 마치, hidden layer의 출력값에 표준화를 적용해준다는 것과 비슷합니다.

신경망의 입력으로 사용할 데이터에 표준화를 적용하는 것과 그렇지 않은 것의 성능 차이는 여러 가지 데이터셋에서도 확인해 볼 수 있습니다. 이를 알면 위에서 말한 장점처럼 수학적으로 자세히 증명하지 않아도, BN이 좋은 성능을 이끌어내고 있다고 느낌적으로 생각해볼 수 있습니다.
Lipschitz Function
(위키 백과) 립시츠 함수는 두 점 사이의 거리를 일정 비 이상으로 증가시키지 않는 함수이다.
검색해보면 흔히 볼 수 있는 수식은 아래와 같다.
$$\left| f(x) - f(y)\over x - y\right| <= K$$
립시츠 조건이 성립하면 균등연속함수(역은 필수는 아님)이므로 해당 범위에서 미분이 가능하며, 미분 계수는 정해진 K 값을 넘을 수 없게 됩니다. 즉, 쉽게 해석해보면 립시츠 함수일때 기울기가 K를 넘지 않으므로 gradient exploding과 같은 문제를 예방할 수 있습니다. 이 점만 기억하면 논문의 주장을 충분히 이해할 수 있습니다.
BatchNormalization은 내부 공변량 변화랑 정말 관계가 있을까?
위에서 설명했듯이 BN은 내부 공변량 변화 문제를 해결한다고 했습니다. 이를 반증하기 위해 논문에서는 한 가지 실험을 수행합니다.
기존처럼 BN을 쓴 것과 여기에 Noise를 추가한 경우를 실험합니다. 노이즈를 추가하는 이유는 일부러 내부 공변량 변화를 발생시키기 위함입니다. 빨간색 분포를 보면 Layer를 거칠수록 파란색, 주황색 분포보다 더욱 불안정함을 알 수 있습니다. 하지만 성능을 확인해보면 내부 공변량 변화 존재 유무를 떠나서 거의 비슷하거나 또는 Noise를 추가한 모델이 더 좋은 성능을 보여주고 있다는 것을 볼 수 있습니다.
여기서 바로 BN이 주고 있는 성능 향상의 원인이 내부 공변량 변화에 크게 치우쳐져 있지 않음을 알 수 있습니다.

심지어 BN을 쓴다고 해서 내부 공변량 변화가 해결되지 않고, 완전히 심각한 문제를 일으키는 경우도 있습니다.

BatchNormalization은 그럼 무슨 역할을 하고 있을까?
이후에도 논문에서는 BN이 내부 공변량 변화와 약한 관계를 가지고 있음을 실험적으로 증명합니다. 그럼에도 불구하고 BN을 사용하면 성능 향상이 일어날 뿐더러 training 과정이 BN을 사용하지 않은 경우보다 더욱 stable함을 보여주고 있다는 것이죠.
왜 잘될까요? 논문에서는 BN을 optimization 관점으로 바라보아야 한다고 주장합니다. 일반적으로 신경망이 가지는 land-scape는 non-convex하고, unstable하기 때문에 loss function을 최적화하는데 문제점을 가지고 있습니다. 따라서 이 논문은 "BN이 내부 공변량 변화를 해결한다기 보다는 이러한 문제점을 해결해주고 있는 것이 아닐까?" 라고 생각합니다.
그럼 이 논문에서 BN을 통해 밝힌 것은 다음과 같습니다.
- optimization problem의 landscape를 더욱 smooth하게 만들어줍니다.
- Loss function이 립시츠해져서 loss의 gradient가 더욱 smooth해집니다. 이러한 결과는 향후 학습에서 gradient가 더욱 reliable해지고, predictive하게 만든다고 합니다.
- predictive가 어느정도 보완되기 때문에 gradient based optimization problem에서도 다음 스텝을 밟는데 있어 어느정도 위험을 배제할 수 있다.
2번 실험에 관한 내용은 다음 figure에서 확인할 수 있습니다.
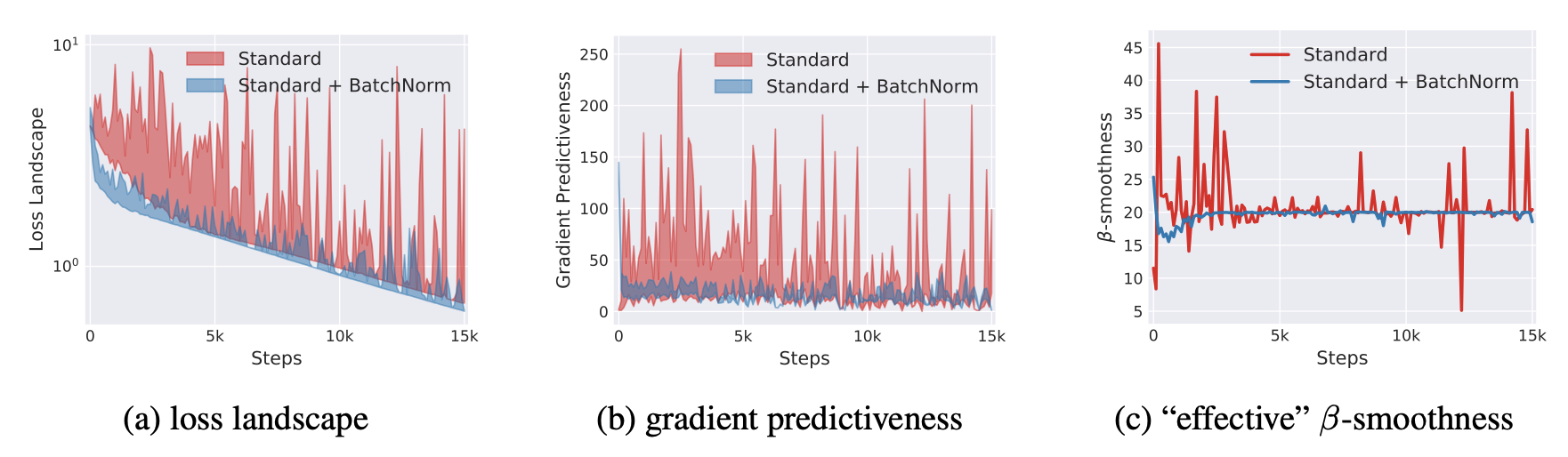
자세한 수학적 증명은 논문을 통해 확인하시길 바라고, 그 중 하나를 보자면,,
아래 그림에서 오른쪽의 $\gamma^2 \over \sigma^2$가 립시츠 함수에서 상수 역할을 하기때문에 왼쪽 항의 Loss function에서 발생하는 gradient가 smooth 될 수 있다고 합니다.

Reference
www.slideshare.net/HoseongLee6/how-does-batch-normalization-help-optimization-paper-review
ko.wikipedia.org/wiki/립시츠_연속_함수
www.youtube.com/watch?v=hiN0IMM50FM&list=PLWKf9beHi3TgstcIn8K6dI_85_ppAxzB8&index=34
'# 기타 공부한 것들 > math' 카테고리의 다른 글
| Numerical Feature Engineering, Gaussian Rank 예제 (0) | 2022.02.19 |
|---|---|
| Bayes 정리: 간단 예제로 이해하기 (0) | 2020.06.01 |
| 균등분포(균일분포, Uniform dist) (0) | 2019.02.26 |
| 지수분포 (1) | 2019.02.22 |
| 다항분포(multinomial distribution) (0) | 2019.02.14 |