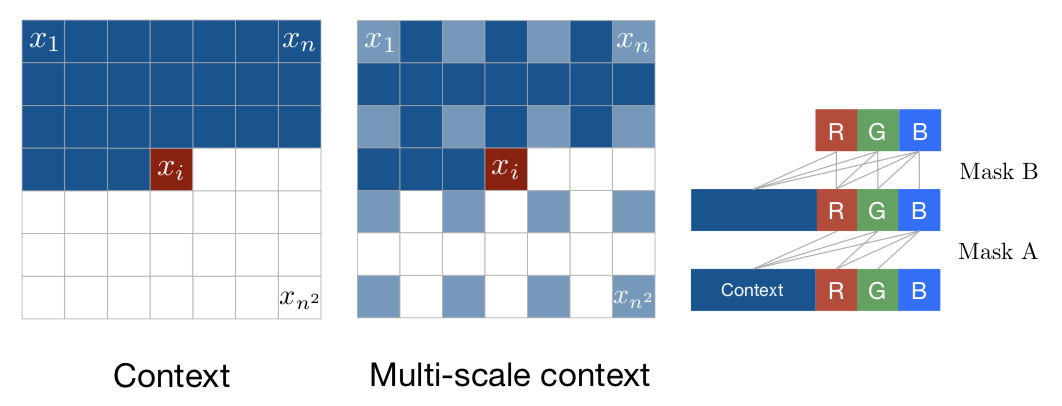
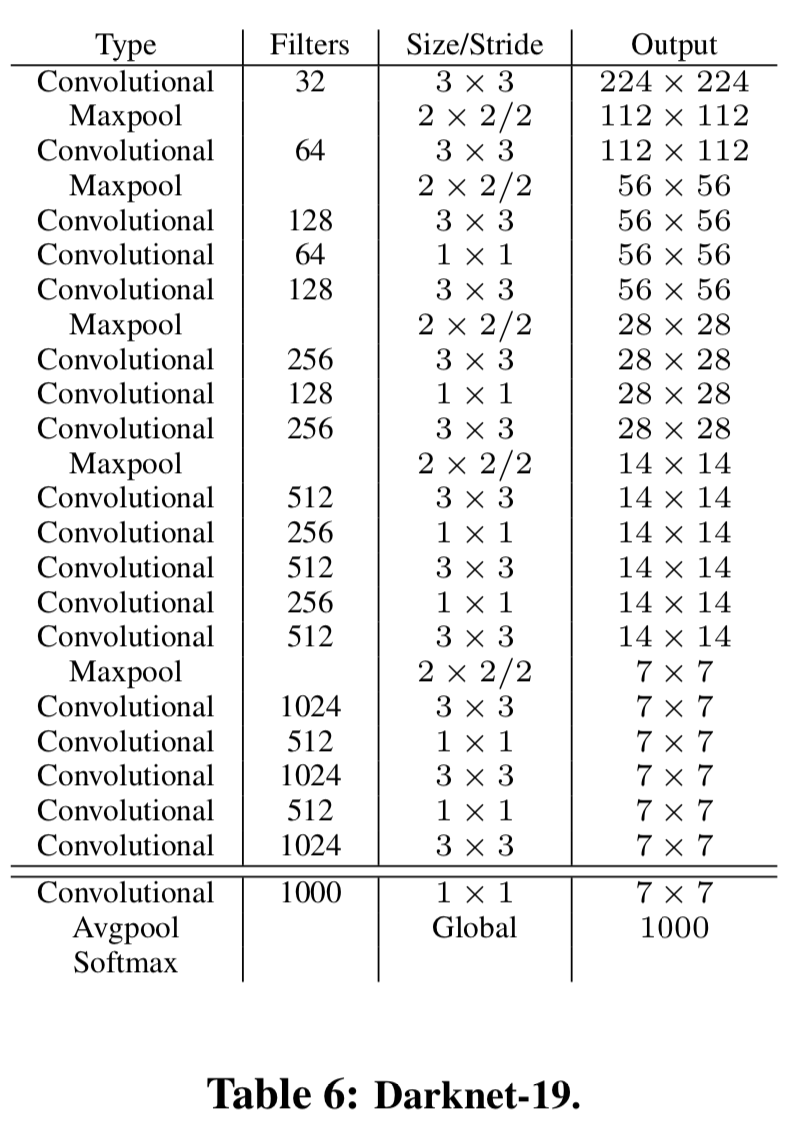
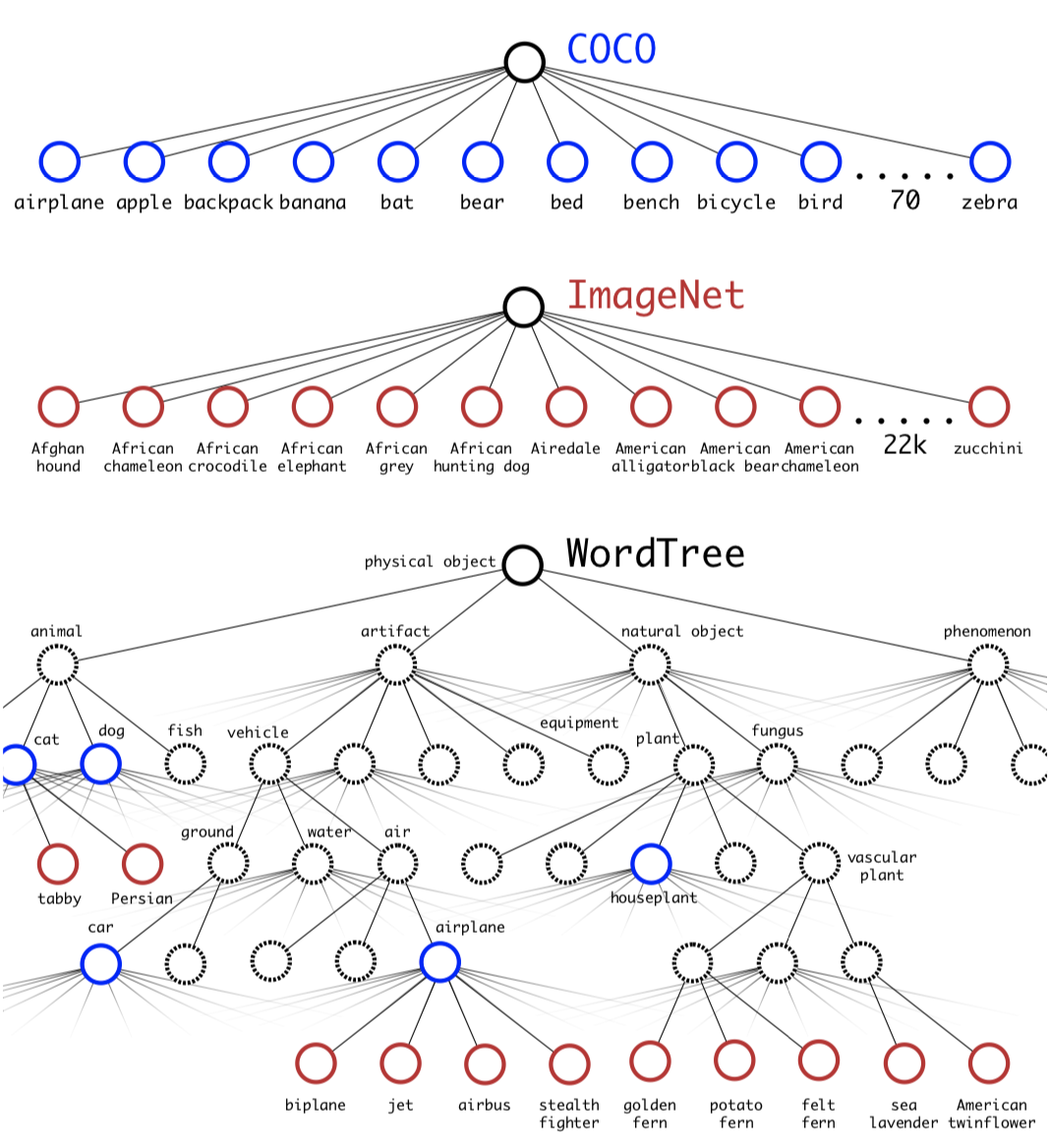
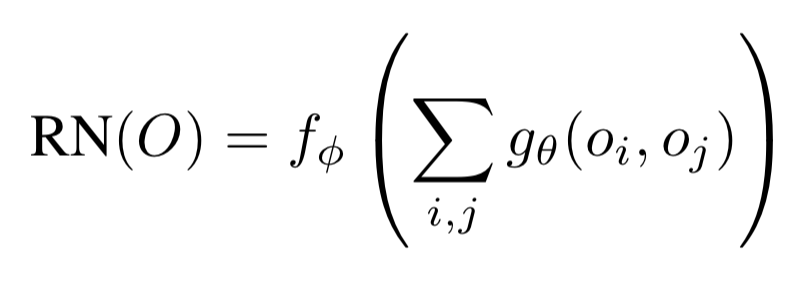Abstract
We present a modality hallucination architecture for training an RGB object detection model which incorporates depth side information at training time. Our convolutional hallucination network learns a new and complementary RGB image representation which is taught to mimic convolutional mid-level features from a depth network. At test time images are processed jointly through the RGB and hallucination networks to produce improved detection performance. Thus, our method transfers information commonly extracted from depth training data to a network which can extract that information from the RGB counterpart. We present results on the standard NYUDv2 dataset and report improvement on the RGB detection task.
우리는 학습 시에 깊이 정보를 포함한 RGB 객체 탐지 모델의 학습을 위해 madality hallucination architecture방법을 소개한다.
컨볼루션 할루시네이션 네트워크는 깊이 네트워크로부터 컨볼루션의 중간 단계 feature들을 모방하기 위해 학습되는 새로운 그리고 보완적인 RGB 이미지 표현을 학습한다.
테스트 단계에서 이미지는 향상된 탐지 성능을 생성할 수 있는 할루시네이션 네트워크와 RGB 네트워크를 동시에 거친다.
우리의 방법은 깊이 학습데이터에서 얻어진 정보를 RGB 정보를 추출할 수 있는 네트워크로 전송한다.
우리는 RGB 탐지 작업에서의 향상과 NYUDv2 데이터 세트에서의 결과를 소개한다.
요약
- 테스트를 진행할 때, Depth 정보가 없는 것이 문제이다. 그런데 이를 생성하기는 힘들고 매우 어렵다. 그래서 대응 방안으로 깊이 정보에 대한 특징을 미리 학습시켜놓고 이를 이용하는 것이다.
- 밑 그림의 모델에서 테스트 시에는 깊이 정보가 없어 빨간 네트워크가 없다. 따라서, 파란색 네트워크를 빨간색 네트워크와 최대한 같게 만들어 이를 테스트시에 활용하여 깊이정보를 생성해낸다.
- 파란색 네트워크에서 할루시네이션은 input 근처의 네트워크에서는 잘 안되고 중간 층 이후부터 학습이 잘 된다.
- 매우 간단한 논문이지만, 평소 우리가 실험할 때 깊이, 위치 등 이미지의 세부 정보를 직접 주지 않아도 모델이 직접 추론하여 추가 정보를 뽑아내게끔 하는 아이디어는 좋다.


Reference
Hoffman, J., Gupta, S., & Darrell, T. (2016). Learning with side information through modality hallucination. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 826-834).
'# Paper Abstract Reading' 카테고리의 다른 글
| Learning to learn by gradient dscent by gradient dscent (0) | 2019.10.26 |
|---|---|
| Photo-Realistic Single Image Super Resolution Using a GAN (0) | 2019.10.12 |
| Pixel Recurrent Neural Network (0) | 2019.09.23 |
| YOLO9000: Better, Faster, Stronger (2) | 2019.09.21 |
| Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification (0) | 2019.09.19 |