이번 글은 PR12의 유재준님께서 Inception과 Xception을 동시에 다루는 관계로 Abstract는 생략하고 바로 요약단계로 넘어가는 것으로 하겠습니다. PR12는 현재 Season 3까지 만들어져, 현재 진행중인 스터디입니다. 블로그에 게시되는 논문은 주로 Season 1에서 다루는 것들을 공부합니다. 이 글이 부족하다면 다음 유재준님께서 발표하신 영상을 보시면 되겠습니다.
링크로는 유튜브 대신 유재준님의 블로그를 올려두겠습니다.
http://jaejunyoo.blogspot.com/2018/02/pr12-video-34-inception-and-xception.html
[PR12-Video] 34. Inception and Xception
Machine learning and research topics explained in beginner graduate's terms. 초짜 대학원생의 쉽게 풀어 설명하는 머신러닝
jaejunyoo.blogspot.com
요약
- Inception을 처음 고안한 모델은 GoogLeNet이다. 모델 구조는 다음과 같다.
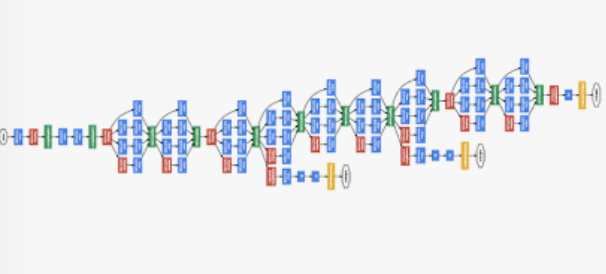
- Xception은 성능 향상을 위해 극단적인 방법을 사용한 구조이다.
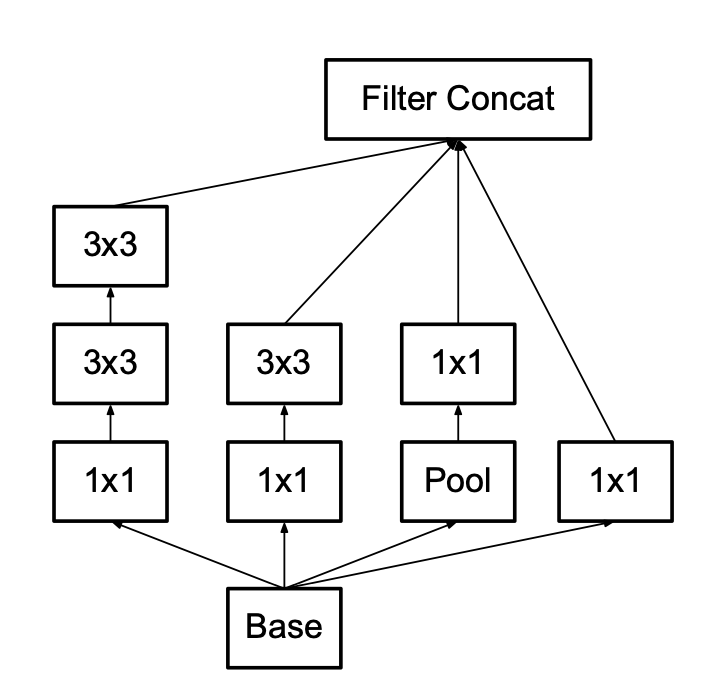
- 먼저 Inception V1은 이미지 분류와 같은 문제를 풀기 위해 더욱 깊게 층을 쌓으려고 한 모델이다. 하지만 깊이 쌓을수록 파라미터의 수가 늘어나고, 컴퓨터 자원적으로도 매우 한계가 있게 된다.
- 이 다음으로 층을 깊게 쌓는 것에 대한 수학적 증명 같은 것을 설명해 주시는데, 결론은 sparse connection을 이용하여 계산을 진행할 경우 수학적으로 좋다고 증명이 되었지만 컴퓨터 자원적으로 단점이 존재한다. 반면, dense connection은 수학적으로 좋지 않다고 증명이 되어있지만, 컴퓨터 자원적으로 효율적이다.
- 기존 Inception 모듈은 1x1 컨볼루션을 사용하지 않은 구조였는데, 이는 파라미터가 급격히 증가되기 때문에 잘 작동하지 않았다. 이를 이유로 1x1 컨볼루션을 파라미터를 효율적으로 줄이고, 표현력을 풍부하게 하도록 하였다.
- Inception V2는 5x5 -> 3x3 + 3x3으로 변경하여 사용하였고, 이를 통해 28%의 파라미터 감소 효과를 누렸다.
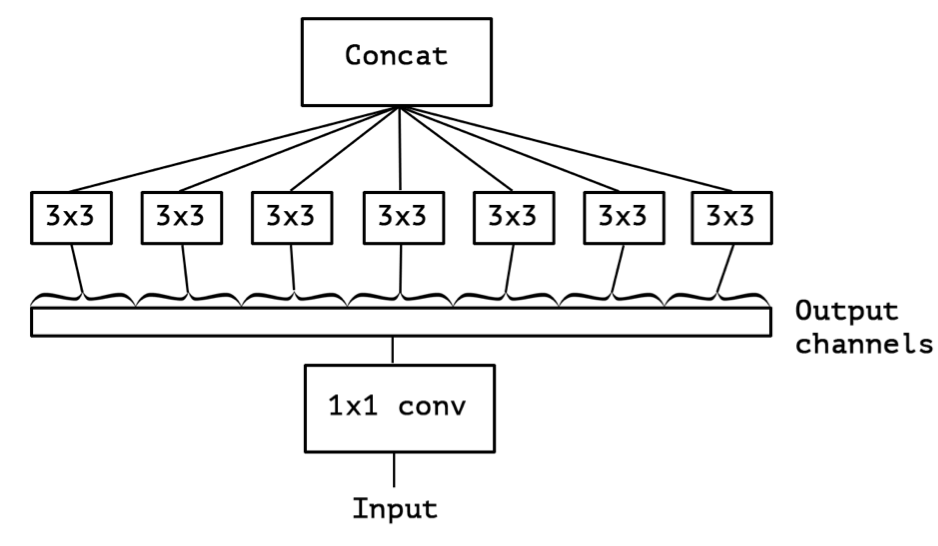
- 이후 Xception 논문에서는 Inception 모듈이 왜 잘되는지에 대해 분석해놓았는데, 첫 번쨰로는 1x1 컨볼루션과 다양한 크기의 컨볼루션을 사용하여 채널별 상관관계와 공간적 상관관계를 동시에 적절히 수행하였다는 점이다.
- Xception은 inception 모듈을 'extreme'하게 표현한 것인데, 여기서 Depthwise separable convolution이라는 용어가 나오게 된다.
- Depthwise separable convolution은 기존의 1x1 -> 3x3의 순서를 3x3 -> 1x1로 변경한 것이다. 이를 다시 말하면 먼저 channel-wise의 연산을 수행한 뒤, point-wise의 연산을 수행한다는 것이다.
- Inception 모듈은 기존 컨볼루션 방식과 Xception 논문에서 나오는 Depthwise separable convolution의 중간 어딘가쯤 존재하는 것이었다. 즉, Xception은 채널, 공간적 관계를 완전히 쪼개서 수행해보겠다는 것이 가설이다.
'# Paper Abstract Reading' 카테고리의 다른 글
| Learning to Remember Rare Events (0) | 2019.12.02 |
|---|---|
| Understanding Black-box Predictions via Influence Functions (0) | 2019.12.01 |
| PVANet: Lightweight Deep Neural Networks for Real-time Object Detection (0) | 2019.10.29 |
| Deep Visual-Semantic Alignments for Generating Image Descriptions (0) | 2019.10.28 |
| Learning to learn by gradient dscent by gradient dscent (0) | 2019.10.26 |













