We introduce an extremely computation-efficient CNN architecture named ShuffleNet, which is designed specially for mobile devices with very limited computing power (e.g., 10-150 MFLOPs). The new architecture utilizes two new operations, pointwise group convolution and channel shuffle, to greatly reduce computation cost while maintaining accuracy. Experiments on ImageNet classification and MS COCO object detection demonstrate the superior performance of ShuffleNet over other structures, e.g. lower top-1 error (absolute 7.8%) than recent MobileNet [12] on ImageNet classification task, under the computation budget of 40 MFLOPs. On an ARM-based mobile device, ShuffleNet achieves ∼13× actual speedup over AlexNet while maintaining comparable accuracy.
연산량에서 매우 제한적인 모바일 환경을 위해 비용 측면에서 매우 효과적인 CNN 아키텍처 ShuffleNet을 소개한다.
ShuffleNet은 pointwise group convolution과 channel shuffle을 통해 정확도를 유지하면서도 연산 비용을 훌륭하게 줄일 수 있다.
ImageNet 분류와 MS COCO 객체 탐지 문제에서 7.8% top-1 error와 40MFLOPs의 매우 낮은 연산 비용을 보여주는 것을 증명하였다.
ARM 기반의 모바일 환경에서 AlexNet보다 13배의 높은 속도를 보여주었으며, 비슷한 정확도를 기록하였다.
요약
기존의 대표적인 CNN 아키텍처는 주로 대부분의 파라미터를 fcn에서 가져가는 경우가 많았는데, MobileNet이나 그 이후의 대표적 CNN 아키텍처들은 1x1 CNN을 사용하게 되면서, fcn이 차지하는 파라미터의 비중보다 1x1 CNN이 차지하는 파라미터의 개수가 더욱 지배적이게 됬다. 그렇다면 이제 1x1 CNN이 차지하는 파라미터를 감소시키는 방법이 없을까에 대한 내용을 다룬다.
AlexNet이 실제로는 GPU 2개를 사용하여 학습하였는데, 여기서 사용한 방법이 group convolution이다.
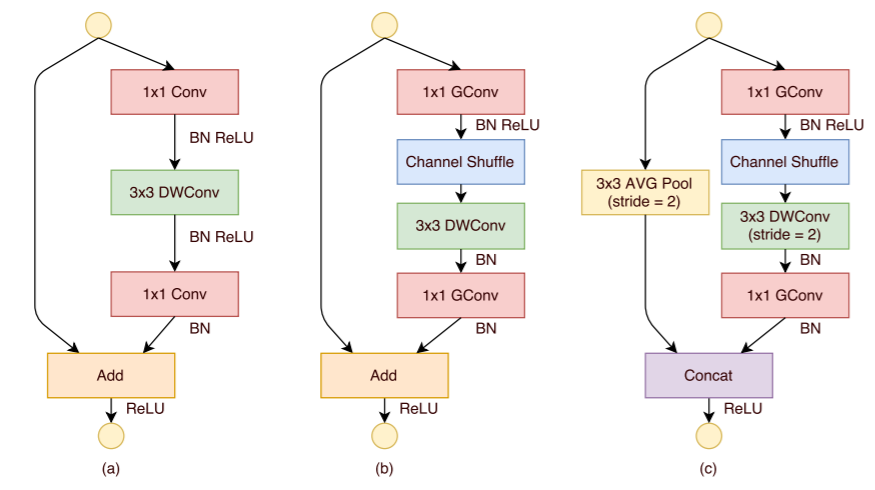
ShuffleNet의 아이디어는 depthwise separable convolution과 channel shuffle을 수행하는 grouped convolution이다. group convolution은 전체 채널에서 컨볼루션 연산 시에 전체 채널을 보기보다는 특정 채널의 범위까지만 다루는 것이다. 이 방법의 문제는 이를 그대로 fcn까지 흘려보내주어 결과를 만들어낼 때, 해당 범위의 채널만 봤기 때문에 제대로 학습되지 않을 수 있는데, 이를 보완하기 위해 shuffle을 해주어 중간중간 해당 그룹이 모든 채널을 볼 수 있도록 도와주게 된다.
ShuffleNet unit은 다음과 같다.
ShuffleNet은 ResNext나 ResNet과 비교하여 연산량 측면에서 우월하다.
연산량을 줄인 장점을 이용하여 채널 수를 늘려 성능면에서도 우수한 것을 보여주었다. group = 8일때 1536개의 채널까지 늘릴 수 있음을 보여주었다.
실험을 통해 항상 그룹의 개수를 많이 가져가는게 좋지 않음을 보여주었지만, 그룹을 일정 수준 이상 나누는게 성능이 좋았고, shuffle을 항상 하는게 좋은 결과를 보여주었다.
MobileNet과의 비교에서 대부분 높은 성능을 보여주었으며, 기타 실험을 통해 모델의 깊이 때문이 아닌 모델 구조에 의해 좋은 성능을 얻음을 보여주고 있다.
Reference
Zhang, X., Zhou, X., Lin, M., & Sun, J. (2018). Shufflenet: An extremely efficient convolutional neural network for mobile devices. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition(pp. 6848-6856).
We propose a technique for producing ‘visual explanations’ for decisions from a large class of Convolutional Neural Network (CNN)-based models, making them more transparent. Our approach – Gradient-weighted Class Activation Mapping (Grad-CAM), uses the gradients of any target concept (say logits for ‘dog’ or even a caption), flowing into the final convolutional layer to produce a coarse localization map highlighting the important regions in the image for predicting the concept. Unlike previous approaches, GradCAM is applicable to a wide variety of CNN model-families: (1) CNNs with fully-connected layers (e.g. VGG), (2) CNNs used for structured outputs (e.g. captioning), (3) CNNs used in tasks with multi-modal inputs (e.g. visual question answering) or reinforcement learning, without architectural changes or re-training. We combine Grad-CAM with existing fine-grained visualizations to create a high-resolution class-discriminative visualization, Guided Grad-CAM, and apply it to image classification, image captioning, and visual question answering (VQA) models, including ResNet-based architectures. In the context of image classification models, our visualizations (a) lend insights into failure modes of these models (showing that seemingly unreasonable predictions have reasonable explanations), (b) outperform previous methods on the ILSVRC-15 weakly-supervised localization task, (c) are more faithful to the underlying model, and (d) help achieve model generalization by identifying dataset bias. For image captioning and VQA, our visualizations show even non-attention based models can localize inputs. Finally, we design and conduct human studies to measure if Grad-CAM explanations help users establish appropriate trust in predictions from deep networks and show that Grad-CAM helps untrained users successfully discern a ‘stronger’ deep network from a ‘weaker’ one even when both make identical predictions. Our code is available at https: //github.com/ramprs/grad-cam/ along with a demo on CloudCV [2] 1 and video at youtu.be/COjUB9Izk6E.
우리는 CNN 모델이 결정하는 가장 큰 클래스를 시각적으로 설명하는 기술을 제안한다.
Grad-CAM은 이미지에서 어떠한 클래스를 예측할 때 중요한 지역을 지역화 맵으로 강조하는 것을 생성하기 위해 마지막 컨볼루션 층에서 흐르는 해당 타겟 클래스가 가지는 그래디언트를 사용한다.
이전 연구와는 다르게 Grad-CAM은 CNN 모델에서 매우 잘 동작한다. (1) fcn이 포함된 VGG와 같은 CNN 모델 (2) captioning과 같은 구조적 아웃풋이 요구되는 CNN (3) 재학습이나 어떠한 구조적 변화가 포함되지 않는 visual Q&A와 같은 multi-modal input을 요구하는 CNN 또는 강화학습
우리는 Grad-CAM에 기존 시각화 방법과 결합하여 고해상도 클래스 시각화 기법인 Guided Grad-CAM을 만들었고, 이를 ResNet 기반의 아키텍쳐를 포함한 VQG 모델, 이미지 캡셔닝, 이미지 분류에 적용해보았다.
이미지 분류문제에서 제안한 시각화는 (a) 비합리적인 예측에는 그만한 이유가 따른다는 것을 제공하여 모델을 설명할 수 있게 하고 (b) 이전 방법보다 우수하며 (c) 기본 모델에서 잘 동작하며 (d) 데이터셋의 편향을 식별하여 모델 일반화를 돕는다.
이미지 캡셔닝과 VQA에서는 non-attention 모델에서도 입력을 지역화할 수 있음을 보여준다. 마지막으로 만약 Grad-CAM의 설명이 깊은 신경망에서의 예측이 적절한 신뢰를 구성할 수 있도록 사용자를 돕거나, Grad-CAM이 훈련되지 않은 사용자가 동일한 예측을 할 때 강한 깊은 신경망의 기능을 약한 깊은 신경망에서 성공적으로 식별할 수 있도록 도와주는 연구를 수행합니다.
요약
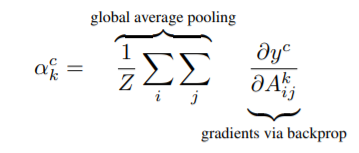
CAM(Class Activation Map)을 확인하는 이유는 모델이 문제를 얼마나 잘 해결하고 있는가를 확인하는 지표가 될 수 있기 때문이다.
강한 신겸망은 사람의 결정이 더 나아질 수 있도록 도와줄 수 있는 모델이고, 약한 신경망은 식별을 실패하는 모델이다.
기존 CAM은 GAP가 존재하지 않으면 사용할 수 없는 문제가 있기 때문에 다양한 CNN 모델에 사용하기 어려웠다.
모델이 해당 클래스를 나타내기 위해서는 특정 클래스를 나타낼 때 클래스에 특징맵이 변화하는 비율을 구하고, 이를 다시 특징맵에 곱해주어 얼마나 영향을 끼치는지를 측정한다.
해당 논문에서는 다양한 실험을 진행해서 보여주고 있다. 대표적으로 Grad-CAM을 통해 데이터셋의 편향을 체크할 수 있으며, 이미지에서 어떤 클래스를 선택했을 때 그게 왜 아닌지를 또한 체크해볼 수 있다.
Reference
Selvaraju, R. R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., & Batra, D. (2017). Grad-cam: Visual explanations from deep networks via gradient-based localization. InProceedings of the IEEE International Conference on Computer Vision(pp. 618-626).
Generative Adversarial Nets [8] were recently introduced as a novel way to train generative models. In this work we introduce the conditional version of generative adversarial nets, which can be constructed by simply feeding the data, y, we wish to condition on to both the generator and discriminator. We show that this model can generate MNIST digits conditioned on class labels. We also illustrate how this model could be used to learn a multi-modal model, and provide preliminary examples of an application to image tagging in which we demonstrate how this approach can generate descriptive tags which are not part of training labels.
GAN은 최근 생성 모델 학습의 대표적 방법으로 소개되고 있다.
이 논문에서는 generator와 discriminator에 우리가 원하는 조건을 지정하여 단순히 데이터를 입력시키는 gan의 conditional 버전을 소개한다.
이 모델은 클래스 레이블에 따라 MNIST 숫자를 생성 할 수 있음을 보여준다.
또한, 이 모델이 multi-modal 모델을 학습할 수 있는 방법을 설명하고, 학습 레이블의 일부가 아닌 설명 태그를 생성할 수 있는 방법을 보여주는 이미지 태깅 app를 설명한다.
요약
기존의 GAN은 데이터를 생성함에 있어서 어떠한 조건도 붙일 수 없는 형태이기 때문에 우리가 원하는 데이터를 생성하는데 제한적이었다.
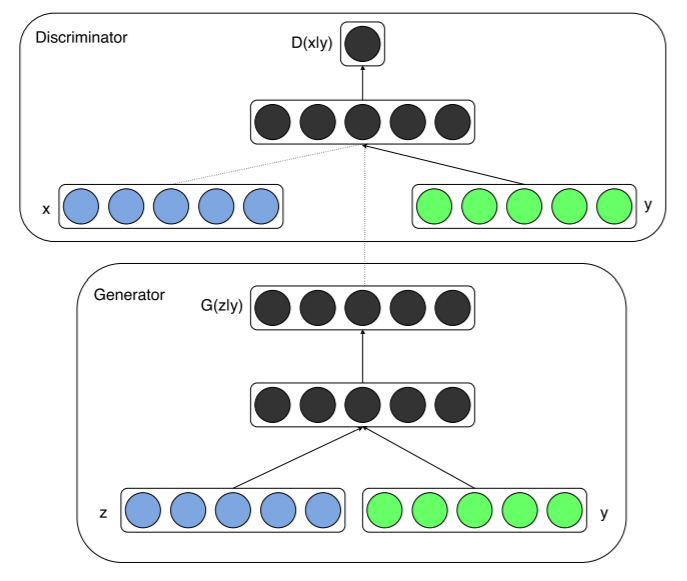
이 논문에서 제안한 모델은 generator나 discriminator에 데이터를 입력할 때 y를 함께 입력해준다(condition)
논문에서는 y라는 조건뿐만 아니라 다른 데이터를 입력시킬 수 있는데, 다른 데이터라면 이미지나 동영상 등이 되겠다. 논문에서는 이미지 태그를 활용했다. 이때, generator에는 random variable z를 입력하고, discriminator에는 유저가 생성한 태그(ground-truth)를 입력해준다. 또한, 컨디션 y로는 동일하게 이미지를 입력시켜준다.
위의 말을 정리하면 (data x, condition data y) == (data G(z), condition daa y) 가 matching 되는지 판단하는 거라고 도영상에서 설명하고 있다.
Reference
Mirza, M., & Osindero, S. (2014). Conditional generative adversarial nets.arXiv preprint arXiv:1411.1784.
The goal of precipitation nowcasting is to predict the future rainfall intensity in a local region over a relatively short period of time. Very few previous studies have examined this crucial and challenging weather forecasting problem from the machine learning perspective. In this paper, we formulate precipitation nowcasting as a spatiotemporal sequence forecasting problem in which both the input and the prediction target are spatiotemporal sequences. By extending the fully connected LSTM (FC-LSTM) to have convolutional structures in both the input-to-state and state-to-state transitions, we propose the convolutional LSTM (ConvLSTM) and use it to build an end-to-end trainable model for the precipitation nowcasting problem. Experiments show that our ConvLSTM network captures spatiotemporal correlations better and consistently outperforms FC-LSTM and the state-of-theart operational ROVER algorithm for precipitation nowcasting.
현재 강우량 예측의 목표는 상대적으로 짧은 기간에 지역의 미래 강우량을 예측하기 위함이다.
대부분의 선행 연구는 이를 핵심적으로 설명해왔고, 머신러닝 관점에서 날씨 예측문제는 도전적이다.
이 논문은 시공간적 시퀀스인 입력과 예측 타겟이 시공간적 예측 문제로서 강수량 예측을 수행한다.
input-to-state, state-to-state으로의 변환에서 컨볼루션 구조를 포함하는 완전 연결 LSTM의 확장으로, 우리는 컨볼루션 LSTM을 제안하고 강우량 예측 문제를 위해 end-to-end 방식의 모델을 구성하였다.
실험은 ConvLSTM이 시공간적 관계를 더 잘 포착해내는 것을 보여주었고, 우수한 성능을 보여주었으며, 강우량 문제에서 사용되는 ROVER 알고리즘과 FC-LSTM보다 우수한 성능을 보여주었다.
요약
국소적인 지역에서 강우량을 예측하는 문제를 다룬다. 이를 위해서 구름 이미지를 사용하게 된다.
기존 강우량 예측에 사용되던 방법은 장점도 있지만, 긴시간 예측에서의 정확도가 떨어지는 등의 문제점을 가지고 있다.
강우량 문제는 과거 J번의 관찰로 미래의 강우량을 예측하게 되는데, 여기서 과거 J번의 관찰을 신경망을 사용하여 인코딩하여 예측에 사용되도록 한다.
기존 Fully-connected LSTM은 시간적 요소만 다루기 때문에 불충분하다. 이를 보완하기 위해 LSTM 식의 앞단에 컨볼루션을 사용하여 지역적(공간적)인 요소를 더해준다.
Moving MNIST와 HKO Radar Echo dataset을 사용하였다.
Reference
Xingjian, S. H. I., Chen, Z., Wang, H., Yeung, D. Y., Wong, W. K., & Woo, W. C. (2015). Convolutional LSTM network: A machine learning approach for precipitation nowcasting. InAdvances in neural information processing systems(pp. 802-810).