Abstract
We propose Efficient Neural Architecture Search (ENAS), a fast and inexpensive approach for automatic model design. In ENAS, a controller discovers neural network architectures by searching for an optimal subgraph within a large computational graph. The controller is trained with policy gradient to select a subgraph that maximizes the expected reward on a validation set. Meanwhile the model corresponding to the selected subgraph is trained to minimize a canonical cross entropy loss. Sharing parameters among child models allows ENAS to deliver strong empirical performances, while using much fewer GPUhours than existing automatic model design approaches, and notably, 1000x less expensive than standard Neural Architecture Search. On the Penn Treebank dataset, ENAS discovers a novel architecture that achieves a test perplexity of 55.8, establishing a new state-of-the-art among all methods without post-training processing. On the CIFAR-10 dataset, ENAS finds a novel architecture that achieves 2.89% test error, which is on par with the 2.65% test error of NASNet (Zoph et al., 2018).
우리는 빠르고 계산 비용이 저렴한 자동화 모델 ENAS를 제안한다.
ENAS에서 컨트롤러는 거대한 계산 그래프에서 최적화된 그래프를 찾아 신경망 아키텍처를 발견한다.
컨트롤러는 검증셋에서의 보상을 최대화하는 서브그래프를 선택하는 정책 그래디언트를 통해 학습된다.
서브그래프에 해당하는 모델은 표준 크로스엔트로피 손실 함수를 최소화하도록 학습한다.
하위 모델간에 매개변수를 공유하는 것은 ENAS가 기존의 자동 모델 설계 방법보다 강력하고, 훨씬 적은 GPU를 사용하며, 1000 배 이상 비용이 저렴하다.
Penn Treebank 데이터셋에서 ENAS는 어떠한 전처리를 거치지 않고 가장 좋은 성능을 달성하였다.
CIFAR-10 데이터셋에서도 ENAS는 NASNet 2.65%에 가까운 2.89%의 테스트 에러를 보여주었다.
요약
- NAS의 방식은 컨트롤러가 하이퍼파라미터를 예측해서 이를 반환해주고, 반환된 하이퍼파라미터를 통해 metric을 산출한 뒤, 이를 reward로 책정하여 강화학습을 통해 모델을 결정하는 방식
- 기존의 NAS는 GPU 시간을 너무 많이 쓰고, 비효율적이라는 문제점이 존재한다. 또, 컨트롤러(RNN)가 뱉어내는 모델마다 새로 학습하기 때문에 병목 현상을 발생시키고 있다.
- 이 논문에서 제안하는 ENAS는 RNN이 뱉어내는 모델의 파라미터를 공유하도록 해서 학습시간을 줄여보자는 것이다.

- 위 그림에서 각 노드는 모델 구성에 결정할 하이퍼파라미터에 대한 정보를 담고 있고, 각 엣지는 어떤 노드로 연결될지를 의미한다. 각 노드안에서 사용한 파라미터는 다음 번에도 사용된다.
- 첫 번째 노드 선택은 고정, 이후 노드 선택은 랜덤, 마지막 노드 선택은 남은 노드를 전부 선택하여 결과를 평균내는 방식으로 진행한다.
- 큰 방식은 전체 모델 구조를 정한 뒤, 노드를 정해서 세부 구조를 정하는 방식.
- 크게 다른 것은 없고, CNN 모델을 구성하는 경우에도 위와 같은 방식을 사용하여 모델을 구성한다는 것을 계속해서 설명한다.
Reference
Pham, H., Guan, M. Y., Zoph, B., Le, Q. V., & Dean, J. (2018). Efficient neural architecture search via parameter sharing. arXiv preprint arXiv:1802.03268.
https://www.youtube.com/watch?v=fbCcJaSQPPA&list=PLWKf9beHi3Tg50UoyTe6rIm20sVQOH1br&index=69
'# Paper Abstract Reading' 카테고리의 다른 글
| Net2Net: Accelerating Learning via Knowledge Transfer (0) | 2020.02.01 |
|---|---|
| DEEP COMPRESSION: COMPRESSING DEEP NEURALNETWORKS WITH PRUNING, TRAINED QUANTIZATIONAND HUFFMAN CODING (1) | 2020.01.29 |
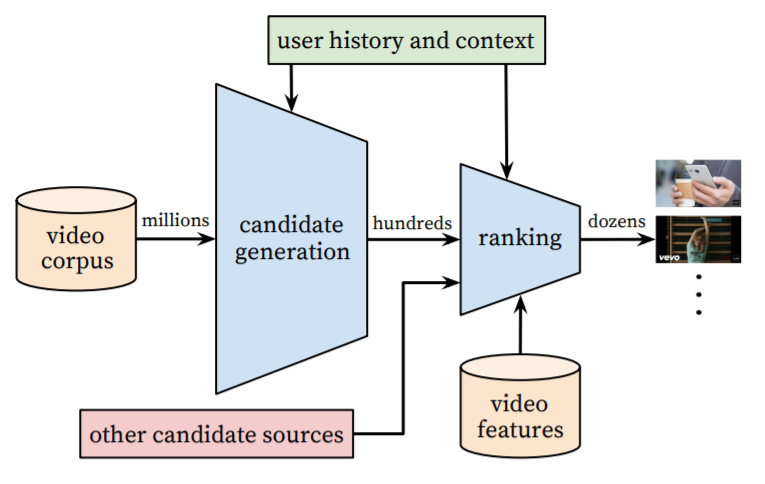
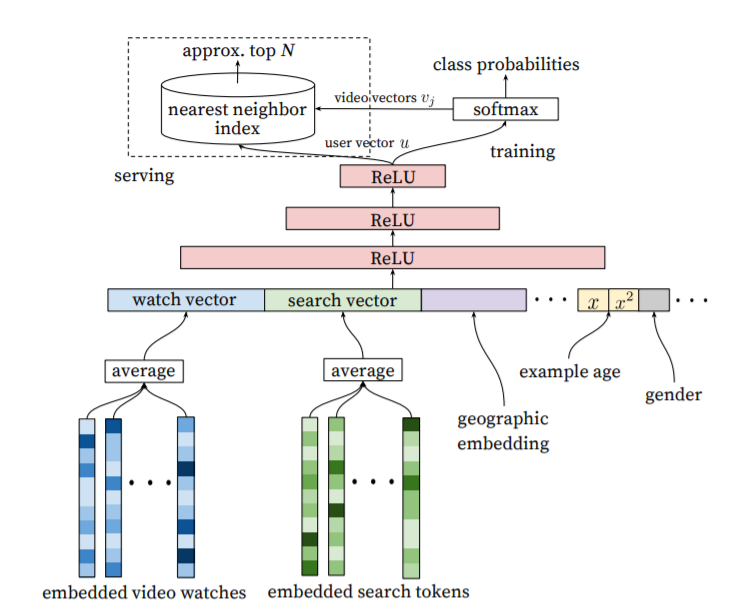
| Deep Neural Networks for YouTube Recommendations (0) | 2020.01.16 |
| Style Transfer from Non-Parallel Text by Cross-Alignment (0) | 2020.01.16 |
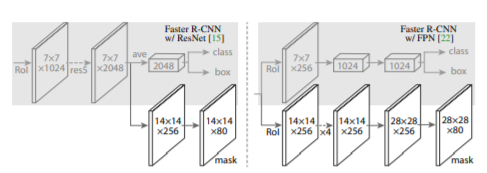
| Mask R-CNN (0) | 2020.01.16 |