In this work, we revisit the global average pooling layer proposed in [13], and shed light on how it explicitly enables the convolutional neural network (CNN) to have remarkable localization ability despite being trained on imagelevel labels. While this technique was previously proposed as a means for regularizing training, we find that it actually builds a generic localizable deep representation that exposes the implicit attention of CNNs on an image. Despite the apparent simplicity of global average pooling, we are able to achieve 37.1% top-5 error for object localization on ILSVRC 2014 without training on any bounding box annotation. We demonstrate in a variety of experiments that our network is able to localize the discriminative image regions despite just being trained for solving classification task1.
이 논문에서는 제안된 GAP에 대해 살펴보고, 이미지 단위의 레이블로 학습했음에도 불구하고 뛰어난 지역화 성능을 보여주는 CNN이 어떻게 그럴 수 있는지에 대해 살펴본다.
이 기술은 학습을 정규화하는 목적으로 사용되지만, 실제로 CNN이 이미지에 대한 암시적 관심을 노출시키는 일반적인 지역화가 가능한 심층 표현을 학습할 수 있는 것으로 나타났다.
GAP의 단순성에도 불구하고, bbox annotation을 학습에 사용하지 않고서도 ILSVRC 2014 객체 지역화 대회에서 37.1% top-5 error를 달성하였다.
우리는 다양한 실험에서 분류를 위해 학습되었음에도 불구하고, 이러한 모델이 객체 지역화에서 잘 작동할 수 있음을 보여준다.
요약
단순 classification 문제로 신경망을 학습시켰을 때, 모델이 해당 이미지에서 주요 객체를 지역화시킬 수 있는지에 대해 알아본다.
관련 연구로는 GAP(Global Average Pooling)이 있으며, 이 개념은 NIN(Network in Network)에서 나옴. GAP의 사용은 대표적으로 기존 모델 구성 시에, FCN(fully connected layer)가 오버피팅을 발생시키기 쉽기 때문에 이를 해결하기 위해서 사용됨. 또한, FCN은 단순 연결하는데 비해 GAP는 채널 별 Sum을 가져다 쓰므로 모델이 이미지를 이해하는데 더욱 도움을 준다고 한다.
모델 설명을 위해 자주 사용되는 Grad-CAM에서의 CAM에 대한 내용이 이 논문의 대부분이다.
GAP와 GMP의 비교도 해주게 되는데, 이는 단순하게 MaxPooling과 Average Pooling의 차이와 비슷하다. 결과적으로 GAP는 activation에서 활성화를 시키려면 대부분의 픽셀이 영향을 주어야 활성화가 진행되기 때문에 지역화에 좀 더 영향을 크게 미친다.
Localization의 높은 성능을 위해서는 Classification의 성능 또한 중요하다.
논문에서는 계속해서 GAP를 추가한 것과 그렇지 않은 것 + Weekly-supervised에 관한 실험에 대한 내용을 설명한다. 밑의 그림에서 green box는 ground truth이고, red box는 실험 결과이다.
마지막으로 논문에서 보면 GAP를 활용하면 다양한 주제에서 적절한 성능을 얻을 수 있다는 실험을 보여주는 것 같다.
Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., & Torralba, A. (2016). Learning deep features for discriminative localization. InProceedings of the IEEE conference on computer vision and pattern recognition(pp. 2921-2929).
In this work we address the task of semantic image segmentation with Deep Learning and make three main contributions that are experimentally shown to have substantial practical merit. First, we highlight convolution with upsampled filters, or ‘atrous convolution’, as a powerful tool in dense prediction tasks. Atrous convolution allows us to explicitly control the resolution at which feature responses are computed within Deep Convolutional Neural Networks. It also allows us to effectively enlarge the field of view of filters to incorporate larger context without increasing the number of parameters or the amount of computation. Second, we propose atrous spatial pyramid pooling (ASPP) to robustly segment objects at multiple scales. ASPP probes an incoming convolutional feature layer with filters at multiple sampling rates and effective fields-of-views, thus capturing objects as well as image context at multiple scales. Third, we improve the localization of object boundaries by combining methods from DCNNs and probabilistic graphical models. The commonly deployed combination of max-pooling and downsampling in DCNNs achieves invariance but has a toll on localization accuracy. We overcome this by combining the responses at the final DCNN layer with a fully connected Conditional Random Field (CRF), which is shown both qualitatively and quantitatively to improve localization performance. Our proposed “DeepLab” system sets the new state-of-art at the PASCAL VOC-2012 semantic image segmentation task, reaching 79.7% mIOU in the test set, and advances the results on three other datasets: PASCAL-Context, PASCAL-Person-Part, and Cityscapes. All of our code is made publicly available online.
이 논문에서는 딥러닝에서의 의미론적 객체 분할 작업과 세 가지의 주요 기여에 대해 설명한다.
첫 번째, dense한 예측(예를 들면, pixel 단위의 예측)에서 강력한 도구인 'atrous convolution'을 강조한다.
Atrous Convolution은 깊은 합성곱 신경망에서 계산되는 특징 반응을 명확하게 제어할 수 있다.
또한, 계산량을 증가시키는 파라미터 수의 증가 없이 큰 맥락을 통합할 수 있는 필터의 관점을 효율적으로 크게 사용할 수 있다.
두 번째, 여러 크기로 객체를 견고하게 세분화 할 수 있는 ASPP(Atrous Spatial Pyramid Pooling)을 제안한다.
ASPP는 다중 샘플링 속도와 효율적인 FOV(Field of View)에서 필터를 사용하여 들어오는 컨볼루션 피처 레이어를 조사하며, 다양한 크기의 이미지 맥락뿐만 아니라 객체를 캡쳐할 수도 있다.
세 번째, DCNN과 확률적 그래프 모델을 방법을 결합하여 객체 경계의 제역화를 개선한다.
일반적으로 DCNN에서 다운샘플링과 맥스풀링의 조합은 불변성이라는 장점을 가지고 있지만, 지역화 정확도에 좋지 않다.
우리는 이러한 문제를 CRF(fully connected Conditional Random Field)를 사용하여 해결하려 한다.
우리가 제안한 'DeepLab' 시스템은 PASCAL VOC-2012에서 SOTA를 달성하였으며, PASCAL-Context, PASCAL-Person, Cityscapes에서 향상된 결과를 얻었다.
요약
Semantic Segmentation에서 사용하는 대표적 평가 방법 IOU --> TP / (TP + FP + FN)
atours convolution = Dilated convolution, 기존 컨볼루션에서 픽셀간 거리를 하나 띄워서 필터를 만드는 것
이들의 장점은 receptive field의 크기는 키울 수 있지만, 파라미터는 급격히 증가하지 않는다는 것이다.
확률적 그래프 모델은 CRF는 픽셀이 위치, RGB상으로 비슷한데 Label이 다르면 패널티를 주어 이를 최소화하게 한다. 자세한건 논문의 수식이나 PR12 동영상을 참고. 이를 사용하면 다음과 같이 객체의 경계를 자세하게 구분지을 수 있음
dilated convolution을 사용하면 풀링을 사용하지 않아도 receptive field를 크게 가져가면서 좋은 성능을 얻을 수 있다. 이는 풀링의 장점 중 하나인 파라미터 감소의 효과도 있다.
제안한 ASPP는 Dilated Convolution만으로는 다양한 크기를 보기 힘들며, 이는 resolution(이미지 크기) 유지를 위해 사용한다. 따라서 우리는 Spatial Pyramid Pooling으로 다양한 input 크기를 다루어서 성능 향상을 꽤한다.
Chen, L. C., Papandreou, G., Kokkinos, I., Murphy, K., & Yuille, A. L. (2017). Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs.IEEE transactions on pattern analysis and machine intelligence,40(4), 834-848.
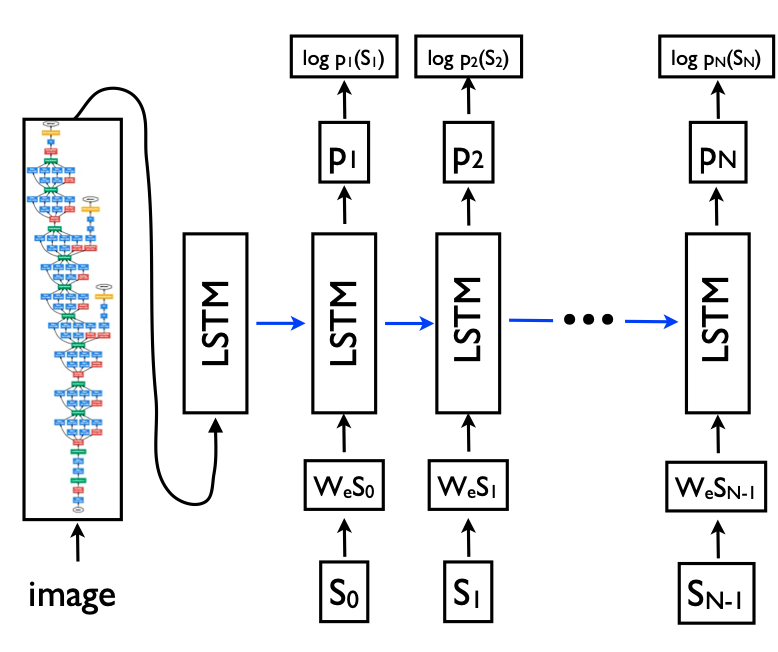
Automatically describing the content of an image is a fundamental problem in artificial intelligence that connects computer vision and natural language processing. In this paper, we present a generative model based on a deep recurrent architecture that combines recent advances in computer vision and machine translation and that can be used to generate natural sentences describing an image. The model is trained to maximize the likelihood of the target description sentence given the training image. Experiments on several datasets show the accuracy of the model and the fluency of the language it learns solely from image descriptions. Our model is often quite accurate, which we verify both qualitatively and quantitatively. For instance, while the current state-of-the-art BLEU-1 score (the higher the better) on the Pascal dataset is 25, our approach yields 59, to be compared to human performance around 69. We also show BLEU-1 score improvements on Flickr30k, from 56 to 66, and on SBU, from 19 to 28. Lastly, on the newly released COCO dataset, we achieve a BLEU-4 of 27.7, which is the current state-of-the-art.
이미지의 내용을 설명하는 것은 컴퓨터 비전과 자연어처리를 연결하는 인공지능의 근본적인 문제이다.
이 논문에서는 컴퓨터 비전과 기계 번역의 최근 발전된 기술을 혼합한 깊은 순환 아키텍쳐에 기반이 되고 있으며 이미지를 설명하는 자연어 문장을 생성가능한 생성 모델을 소개한다.
모델은 주어진 학습이미지를 설명하는 문장을 목표로 liklihood를 최대화하게끔 훈련되어진다.
몇 가지 데이터셋에서의 실험은 모델의 정확성과 이미지 설명으로부터 학습한 언어의 유창성을 보여준다.
본 연구의 모델은 상당히 정확하며 질적, 양적으로 검증되었다.
예를 들면, BLEU-1 score에서 SOTA가 25였다면 우리의 모델은 59나 된다.(인간 69)
우리는 또한 Flickr30k를 사용하여 BLEU-1에서 56 -> 66, SBU 19 -> 28, COCO에서 BLEU-4 27.7을 달성했다.
요약
이미지의 설명을 뽑기 위해 첫 부분에서 GoogleNet을 쓰고, 뒤에 LSTM을 이어붙인 구조를 사용하였다.
모델 구조에서 LSTM으로 이어주기 직전에 이미지 벡터 공간을 워드 벡터 공간으로 매핑시켜주는 레이어를 추가하였다.
이 논문은 word2vec의 사용을 강조하고 있다.(시기 상 나온지 얼마 안된 시점)
기존에 문장 생성 시에 워드 벡터 공간에서 가장 확률이 높은 단어를 사용하는 샘플링 방법을 사용하는데, 이 논문은 이 방법을 사용하지 않고 BeamSearch 기법을 활용하였다. 이 기법은 k 개(논문에서는 20개)의 후보를 항상 유지하여 가장 마지막 단계에서 후보를 선택함. k를 1로 두는 것보다 20으로 두는게 좀 더 성능이 좋았다. 하지만 높을수록 오버피팅의 문제가 심각하였으며, 이 때문에 실제 대회에서는 3으로 줄여서 사용했다.
BLEU-n 평가 방식은 문장에서 단어가 몇개나 정확한가를 평가하는 지표인데, 이미지 캡션에서는 잘 맞지 않는 지표일 수 있다. 예를 들어 BLEU-3은 연속적인 3개의 단어가 얼마나 정확한가에 대한 것 뿐만 아니라 1, 2개의 연속적인 단어에 대해서도 확인하는 것이다. n이 증가할 수록 어려워진다.
학습 시에 오버피팅이 심했는데 이를 해결하기 위해, CNN 부분은 사전 학습 모델을 사용하고 워드 임베딩 벡터는 초기화하지 않고 사용했더니 더 잘되었다. 추가적으로 드롭아웃과 앙상블을 활용했다.
2 단계 학습을 사용했는데, 처음 단계는 Inception 모델의 가중치를 동결시키고 학습시킨 후에 두번째로 Fine-Tune을 수행하였다.
논문이 아닌 대회를 위해서 모델에 일정 부분을 변경하여 참여하게 되었는데, 먼저 Fine-Tune 시에 LSTM를 일정 수준까지 학습한 뒤에 CNN의 Fine-Tune을 수행하였다.
Reference
Vinyals, O., Toshev, A., Bengio, S., & Erhan, D. (2015). Show and tell: A neural image caption generator. InProceedings of the IEEE conference on computer vision and pattern recognition(pp. 3156-3164).