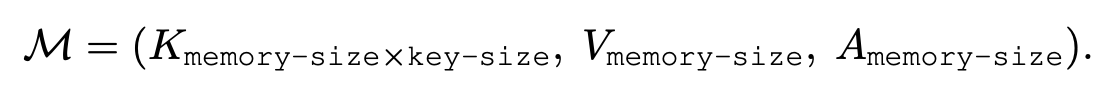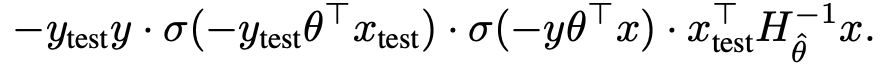ABSTRACT
This paper introduces WaveNet, a deep neural network for generating raw audio waveforms. The model is fully probabilistic and autoregressive, with the predictive distribution for each audio sample conditioned on all previous ones; nonetheless we show that it can be efficiently trained on data with tens of thousands of samples per second of audio. When applied to text-to-speech, it yields state-of-the-art performance, with human listeners rating it as significantly more natural sounding than the best parametric and concatenative systems for both English and Mandarin. A single WaveNet can capture the characteristics of many different speakers with equal fidelity, and can switch between them by conditioning on the speaker identity. When trained to model music, we find that it generates novel and often highly realistic musical fragments. We also show that it can be employed as a discriminative model, returning promising results for phoneme recognition.
이 논문은 audio waveforms를 생성하기 위한 WaveNet을 소개한다.
이 모델은 완전히 확률적이고 오토리그레시브하며, 각 오디오 샘플에 대한 예측 분포를 이전 모든 샘플에 맞춰 조정한다; 그럼에도 불구하고 우리는 초당 수만개의 오디오 샘플을 사용하여 효율적으로 학습이 가능하다는 것을 보여준다.
TTS (text-to-speech)에 적용하면 최첨단 성능을 얻을 수 있으며, 청취자는 영어와 만다린 모두를 위한 최고의 파라메트릭 및 연결 시스템보다 훨씬 더 자연스러운 소리로 평가한다.
단일 WaveNet은 동일한 충실도로 서로 다른 말하는 사람들의 특징을 잡아낼 수 있고, 그들의 본질(남자 목소리, 여자 목소리 등등)을 전환하여 사용할 수 있다.
음악을 학습했을 때, 새롭고 현실적인 음악적 요소를 잘 생성한다는 것을 볼 수 있었다.
또한, 음소 인식에 대해 좋은 결과를 보여주는 적대적 모델로서 사용할 수 있다.
요약
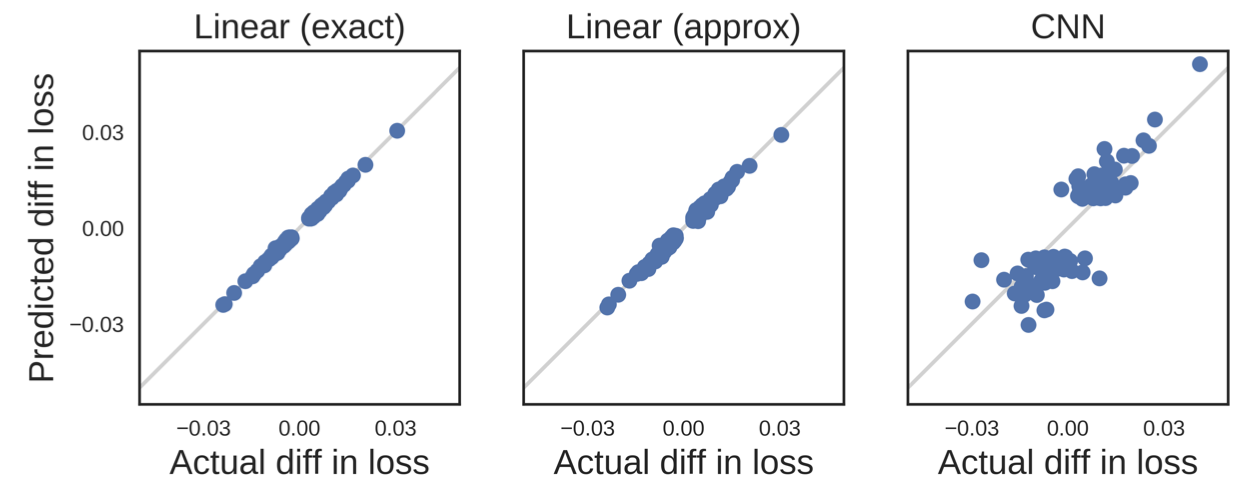
- 이 논문은 확률의 marginalization과 같이 이를 스태킹한 컨볼루션 형태로 표현하겠다는 것이 핵심이다.(Stack of Causal Convolutional Layers)
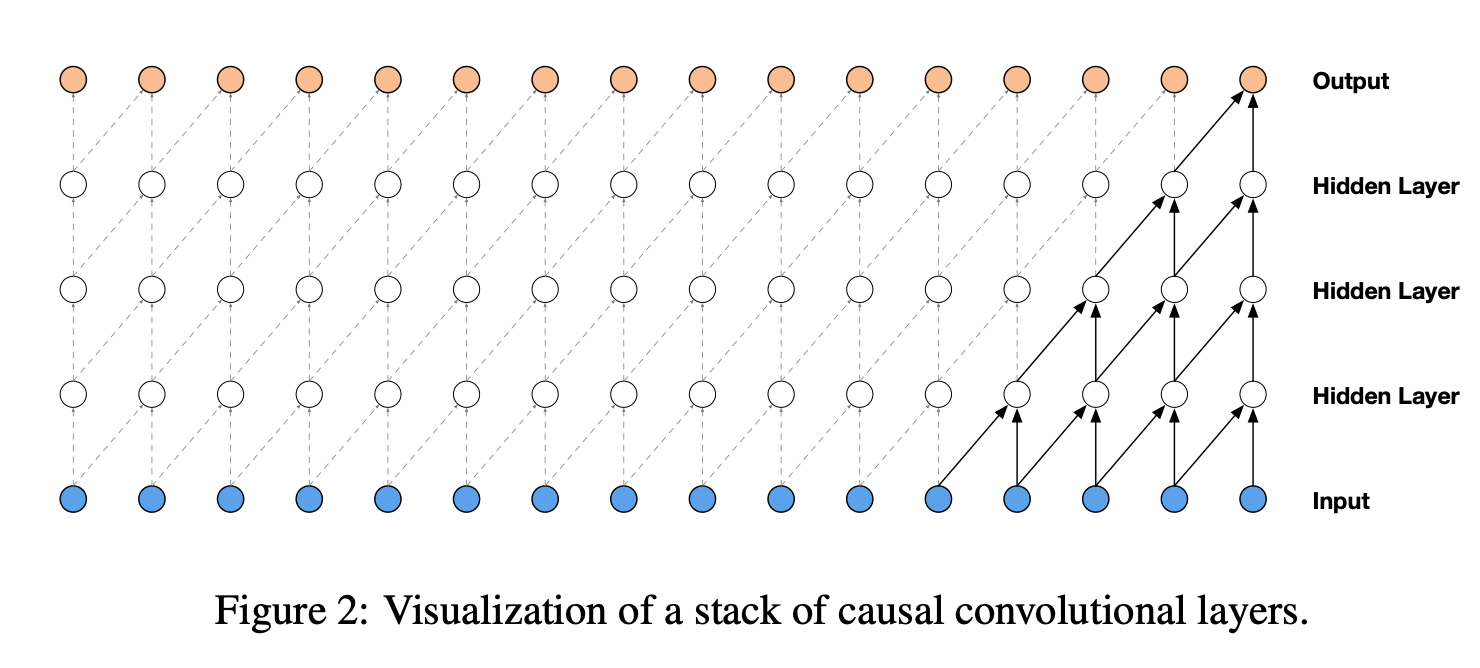
- 위의 그림을 보면, 이전의 샘플을 컨볼루션에 사용하는 것을 볼 수 있다. 예를 들어, input에서 hidden layer로 넘어갈 때 hidden layer는 각각 2개의 파란색 점을 사용함.
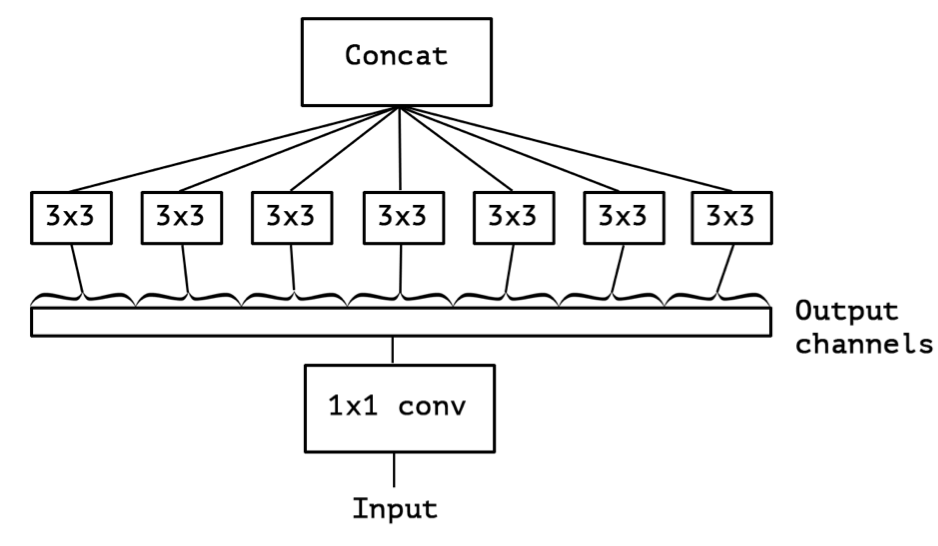
- 하지만 위의 그림에서의 방법은 receptive field가 작기때문에 dilated 방법을 사용한다.
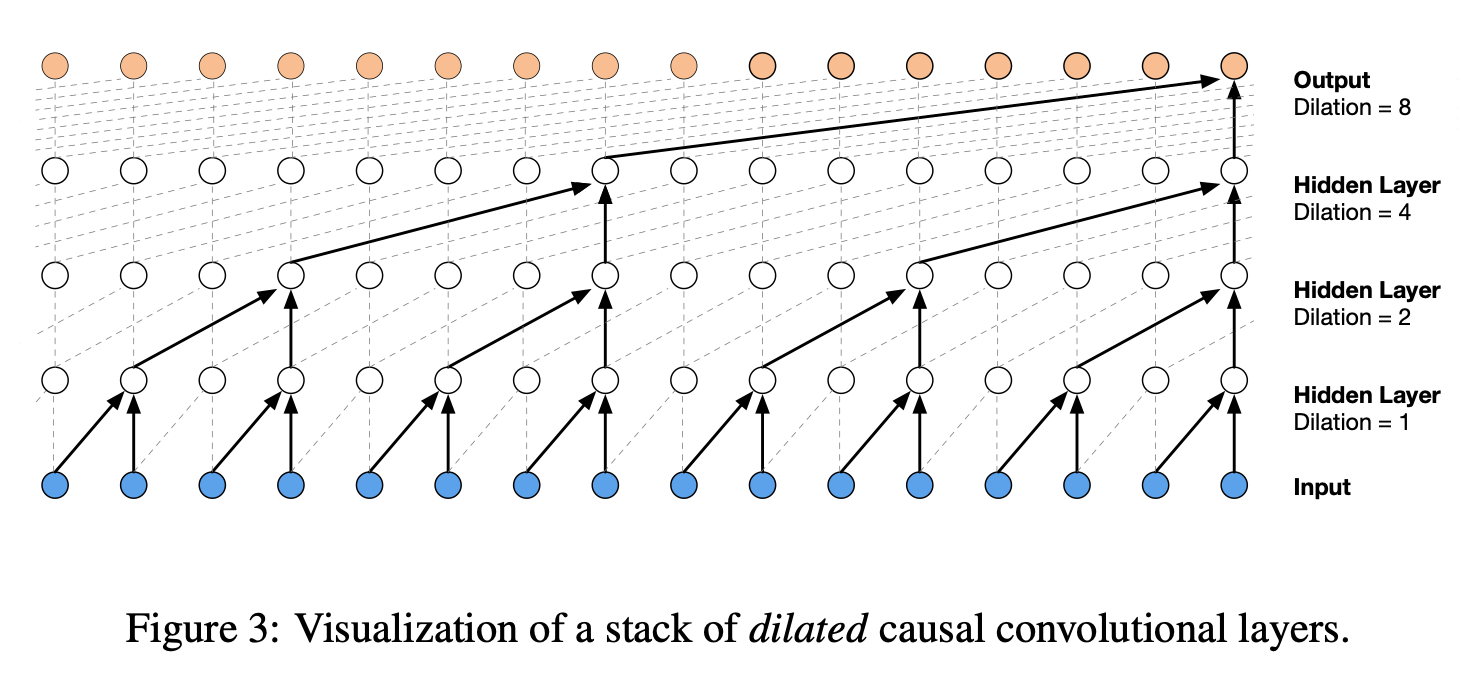
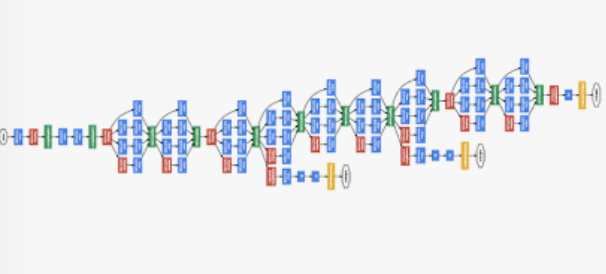
- 아키텍쳐는 다음과 같다.
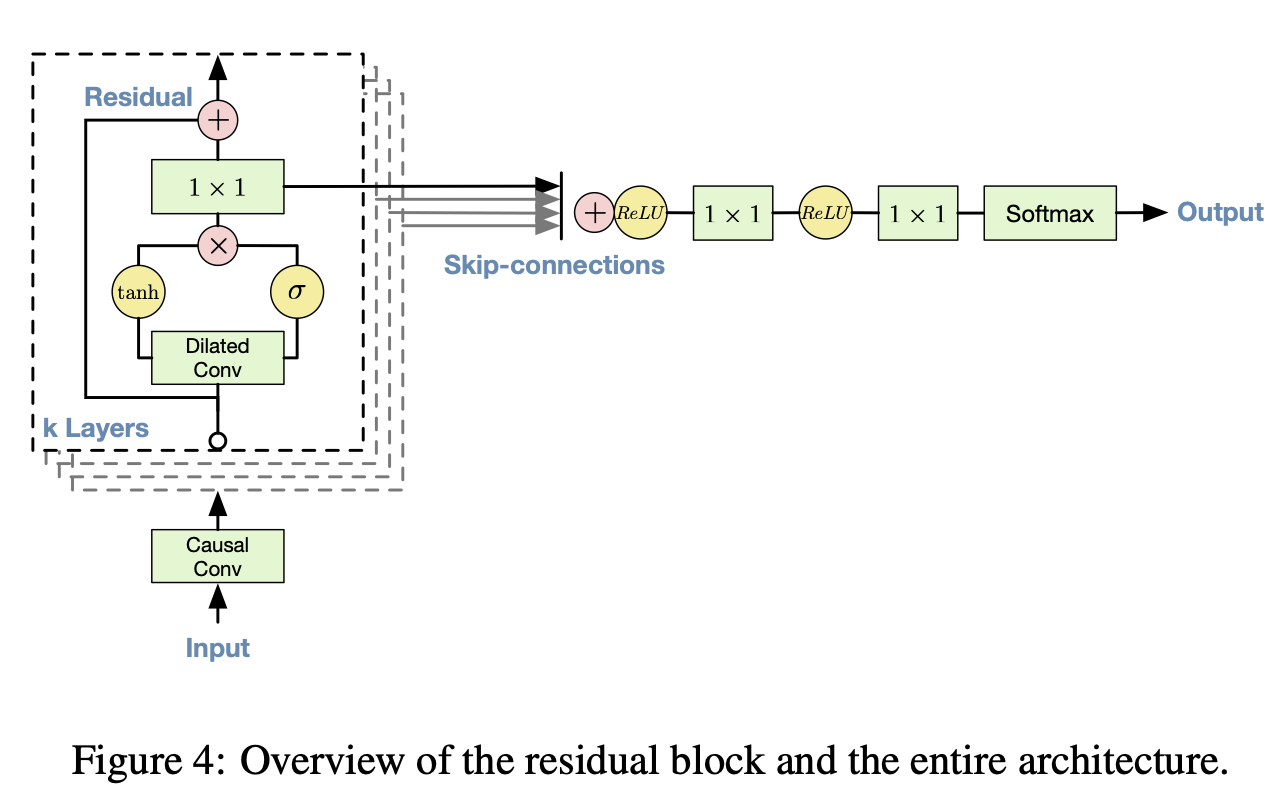
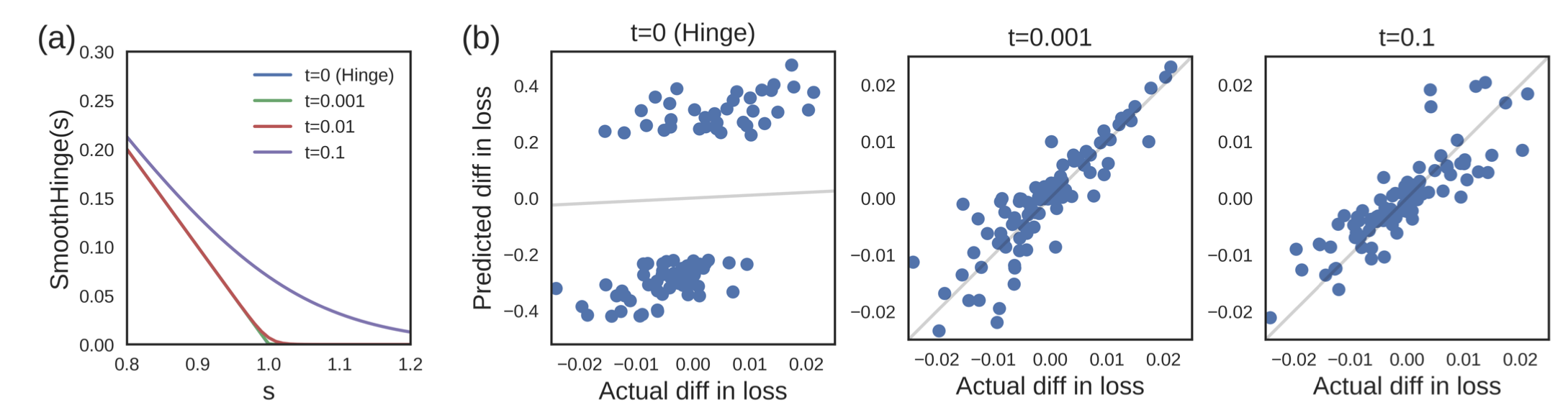
- 마지막으로 Conditional WaveNet은 아래 그림과 같이 h에 어떠한 조건을 걸겠다는 것을 의미한다.
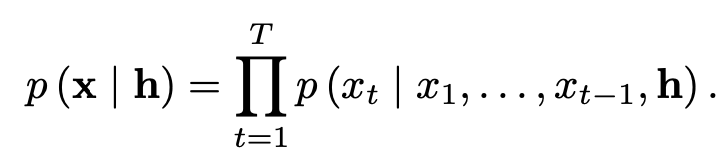
- 두 가지가 있는데, 먼저 Global Conditioning은 목소리와 같은 경우 남자 목소리는 시간이 지나도 남자 목소리이므로, 전체 타임스텝에 같은 조건을 다루도록 한다.
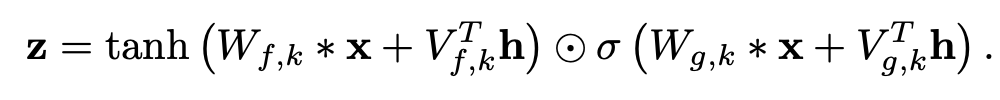
- Local Conditioning은 Condition이 시간에 따라 변하는 것이다. 이는 매우 천천히 변하는 데이터(ex: 텍스트 데이터, 텍스트 데이터는 음성 데이터에 비해 변화가 더 적음)에 적용하기 위해 transposed CNN을 사용하여 크기를 맞춰주고 1x1 CNN으로 더해주게 된다.(밑의 그림에서 V * y에서 y 부분)
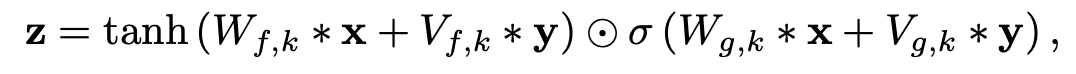
Reference
Oord, A. V. D., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., ... & Kavukcuoglu, K. (2016). Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.03499.
'# Paper Abstract Reading' 카테고리의 다른 글
| DeepLab: Semantic Image Segmentation withDeep Convolutional Nets, Atrous Convolution,and Fully Connected CRFs (0) | 2019.12.20 |
|---|---|
| Show and Tell: A Neural Image Caption Generator (0) | 2019.12.13 |
| Learning to Remember Rare Events (0) | 2019.12.02 |
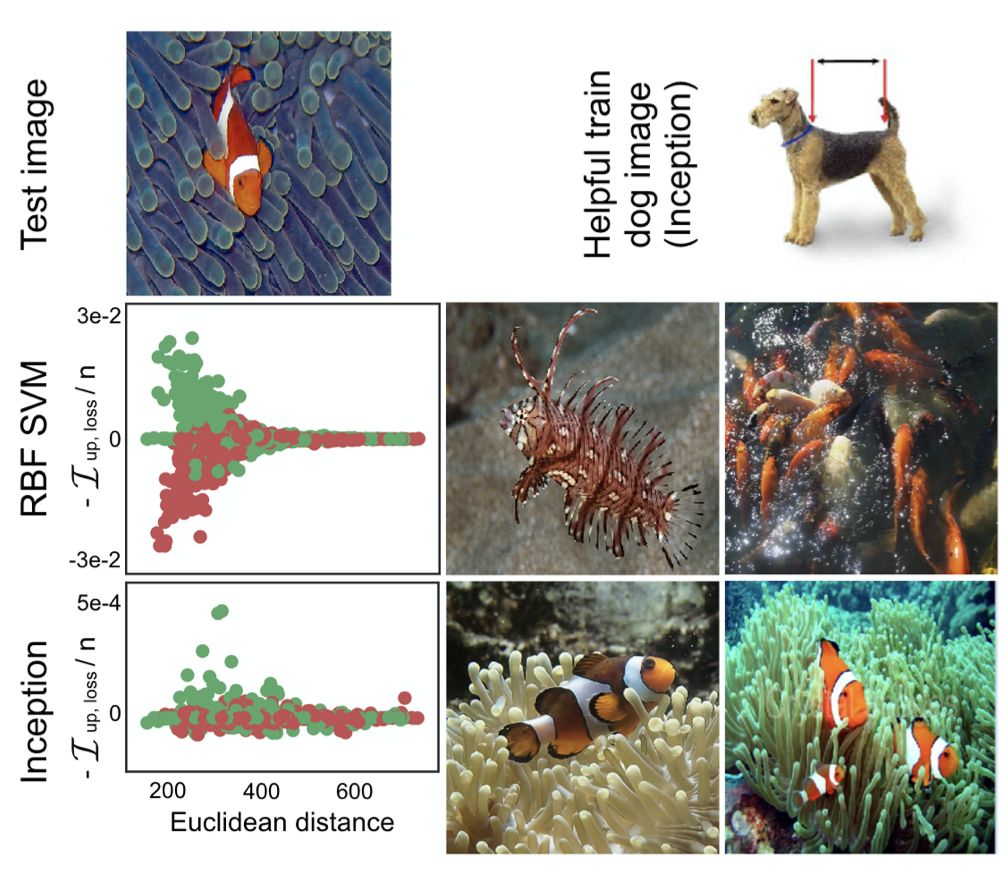
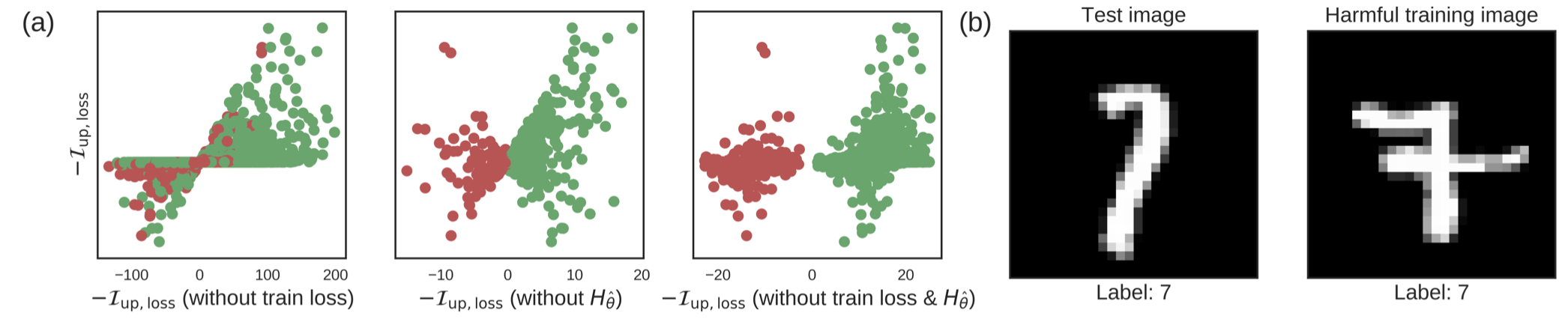
| Understanding Black-box Predictions via Influence Functions (0) | 2019.12.01 |
| Inception and Xception (0) | 2019.11.26 |