Abstract
This paper focuses on style transfer on the basis of non-parallel text. This is an instance of a broad family of problems including machine translation, decipherment, and sentiment modification. The key challenge is to separate the content from other aspects such as style. We assume a shared latent content distribution across different text corpora, and propose a method that leverages refined alignment of latent representations to perform style transfer. The transferred sentences from one style should match example sentences from the other style as a population. We demonstrate the effectiveness of this cross-alignment method on three tasks: sentiment modification, decipherment of word substitution ciphers, and recovery of word order.
이 논문은 non-parallel text에 기초한 style transfer에 대해 다루고 있다.
이것은 기계 번역, 해독 및 감정 변화를 포함한 광범위의 문제를 다룬다.
주요 도전 관점은 컨텐츠를 스타일과 같은 다른 측면과 분리하는 것이다.
우리는 서로 다른 텍스트 corpora를 사용하여 latent content distribution의 공유를 가정하고, style transfer을 위한 잠재 표현의 정렬을 활용하는 방법을 제안한다.
한 가지 스타일로부터 전송된 문장은 모집단으로서 다른 스타일의 예제 문장과 일치해야 한다.
우리는 다음 세 가지 작업에 대해서 교차 정렬 방법의 효율성을 증명한다: 감정 변화, 단어 해독, 단어 순서 복구
요약
- parallel data이라는 것은 positive한 문장이 있을때 negative 문장에서 정반대의 문장이 존재하는 것을 의미한다. 예를 들어서 '나는 차가 좋다' 라는 문장이 있으면 negative에서 '나는 차가 싫다'라는 문장이 있어야하는 것이다. non-parallel은 이와 다르게 '나는 차가 좋다'라는 문장이 있지만, negative에서는 '나는 차가 싫다'라는 문장이 명시적으로 없는 것을 의미한다. 즉, 대칭되는 문장이 없는 것을 의미한다.
- 이 논문은 주로 AE + GAN의 방법을 사용한다.
- 이 논문은 VAE가 좋지 않다고 주장하며 사용하지 않는데, 그 이유는 사용하는 분포를 제한하지 않고 모든 변수를 사용하고 싶다고 한다. 분포를 제한하는 것은 non-parallel 데이터에 부정적인 영향을 끼친다고 설명한다.
- 먼저 제안하는 Aligned AE는 다음 loss를 최소화한다.

- 또, encoder E와 generator G, RNN 1개의 층을 사용하여 학습한다.
- Cross-aligned AE의 구조는 다음 그림과 같다.

- 위의 그림은 x1 -> x2가 먼저 수행되고, 다음으로 x2에서 x1으로 다시 넘어오게 되면서 스타일이 변형된다.
Reference
Shen, T., Lei, T., Barzilay, R., & Jaakkola, T. (2017). Style transfer from non-parallel text by cross-alignment. In Advances in neural information processing systems (pp. 6830-6841).
https://www.youtube.com/watch?v=w-P2V2LlrHg&list=PLWKf9beHi3Tg50UoyTe6rIm20sVQOH1br&index=59
'# Paper Abstract Reading' 카테고리의 다른 글
| Efficient Neural Architecture Search via Parameter Sharing (0) | 2020.01.24 |
|---|---|
| Deep Neural Networks for YouTube Recommendations (0) | 2020.01.16 |
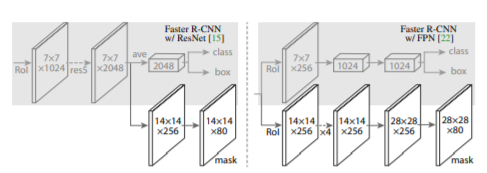
| Mask R-CNN (0) | 2020.01.16 |
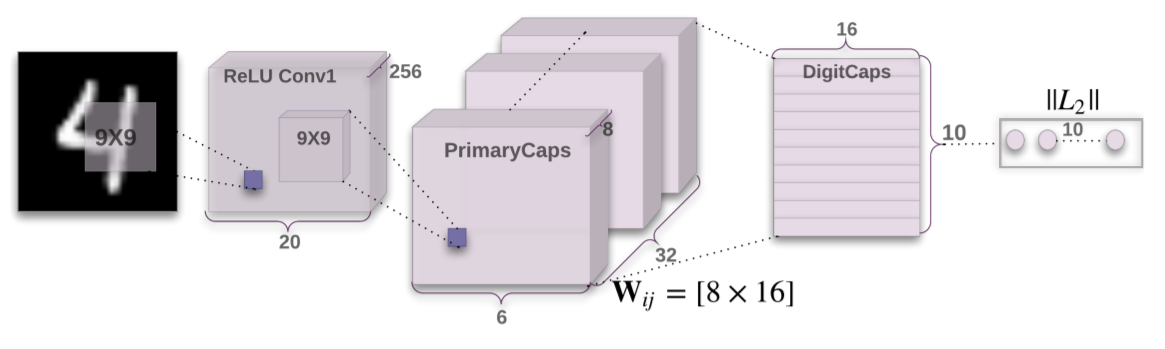
| Capsule Network (0) | 2020.01.16 |
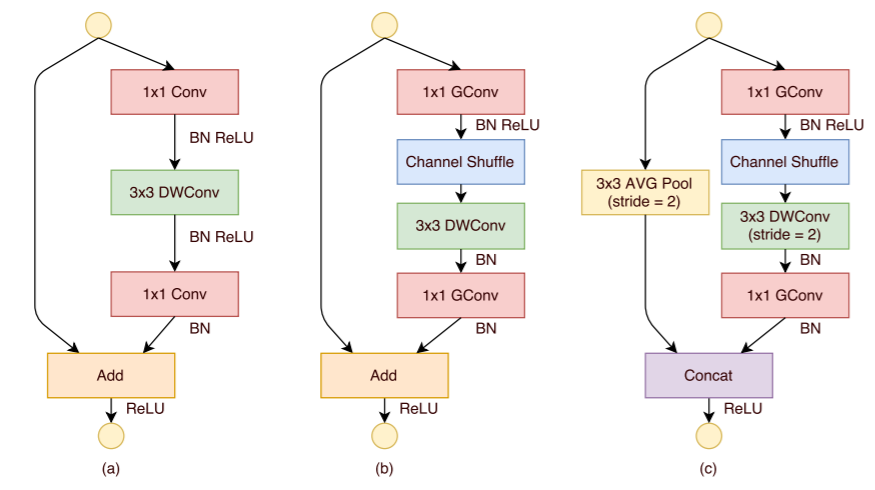
| ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices (0) | 2020.01.13 |